
LinkDB: A Comprehensive Professional Social Network Dataset of Over 485 Million People and Company Profiles
Update from Nubela: Proxycurl, and by extension LinkDB, have been sunset. I am the founder behind Proxycurl, and I am now building NinjaPear, our newer B2B intelligence platform. I am leaving this article up because the underlying explanation of what LinkDB was, how the dataset was structured, and how to work with large LinkedIn-style datasets is still useful. Where relevant, I have updated this post for accuracy.
At the time of posting this article, LinkDB has 485,373,254 public LinkedIn profiles, to be specific. By the time you're reading this, it's even more.
LinkedIn is by far the world's largest professional social media site, and by virtue, the world's largest source of B2B data. If you can tap into its B2B dataset, there are many different interesting things you can do with it.
Anywhere from finding prime investment opportunities, to training AI models, or building the next best SaaS application, and beyond.
LinkDB acts as a data foundation for all kinds of B2B applications.
But the problem is LinkedIn doesn't make it very easy to extract data from their platform, even if you're willing to pay for it. They want to gatekeep it and use it to power their own tools such as LinkedIn Recruiter and Sales Navigator instead.
Thus, a need for things like LinkedIn scrapers, but scraping LinkedIn is never a hassle-free experience. You'll constantly be fixing things and it requires a dedicated web scraping team to scale. This often doesn't make sense for many businesses.
Which is exactly why we created LinkDB. It makes acquiring B2B data easy so that you can focus on implementing the data, rather than acquiring it.
Download a LinkDB sample
We're big believers in not just telling, but showing.
So, if you're interested in downloading either a company or profile LinkDB sample, there are 10,000 real profiles in either export, you can do so below:
Enter your first name:
Enter your email:
HP
Just check your email shortly after submitting the form. This will help you follow along and get the most out of this article.
Continuing on:
What kind of data does LinkDB contain?
LinkDB contains data on both people and companies.
LinkDB's people dataset
You can expect to receive the following data points as part of our people dataset:
- Articles related to the profiles, featuring titles, publication dates, and summaries.
- Activities such as posts, comments, and engagements tied to profiles.
- Certifications individuals hold, listing names, issuing bodies, and acquisition dates.
- Courses completed, noting course titles, institutions, and completion dates.
- Educational background with degrees, institutions, and years attended.
- Professional experience outlining job titles, employers, tenure, and roles.
- Group memberships detailing group names and individual roles.
- Honors and Awards received, with names, issuers, and dates.
- Language proficiencies listing languages and proficiency levels.
- Organization affiliations beyond employment, including names and roles.
- Projects detailing titles, descriptions, durations, and roles.
- Publications authored, including titles, dates, and co-authors.
- Recommendations given or received, with texts and relationship contexts.
- Similar profile names for disambiguation.
- Test scores listing test names, scores, and dates.
- Volunteering experiences including roles, organizations, and durations.
- Core profile information such as names, titles, and summaries.
The core profile schema consists of:
id: Unique identifier for each profile.profile_picture_url: Link to the profile's image.city: Base city of the profile owner.country: Country code and full name, reflecting the profile's national affiliation.first_name: The first name name of the profile owner.last_name: The last name name of the profile owner.headline: The headline of the profile.summary: The summary of the profile.state: State or region for more precise geographical detail.background_cover_image_url: Link to the profile's background image.birth_date: Profile owner's birth date.connections: Network size.follower_count: The number of followers of the account.occupation: Current job title.crawler_name: Source of data collection.
LinkDB's company dataset
For companies, the core schema consists of:
html_url: A URL to the company's profile page.name: The name of the company.description: A detailed description of what the company is about.tagline: Not provided, but would be a succinct statement representing the company's mission or ethos.website: The URL to the company's website.industry: The sector in which the company operates.founded_year: The year the company was established.profile_pic_url: A URL to the company's logo or profile picture.background_cover_image_url: A URL to a background or cover image for the company's profile.search_id: A unique search identifier, possibly related to the database or API query.company_type: Indicates the legal structure of the company.company_size_on_linkedin: The number of employees listed on LinkedIn.company_size_min: The minimum number of employees in the company.company_size_max: The maximum number of employees in the company.follower_count: The number of followers the company has.linkedin_internal_id: A unique identifier within LinkedIn.email_pattern_probed: The pattern used for company email addresses.domain: The internet domain name for the company.
What format does LinkDB come in?
When dealing with large datasets, especially those containing complex nested structures like those found in LinkedIn profiles, the choice of file format becomes rather important.
Traditional formats like CSV or JSON might suffice for smaller datasets, but they quickly become inefficient for larger ones.
This is where Apache Parquet comes into play.
Introducing Parquet
Parquet is a columnar storage format that's optimized for big data processing. It differs from row-based storage formats by storing data column-wise instead of sequentially by row.
This columnar storage allows for efficient compression and encoding schemes that are tailored to the data type of each column, significantly improving query performance. This is especially beneficial for analytics workloads, which typically only access a subset of columns. One of the key features of Parquet is predicate pushdown, which enables query engines to skip entire chunks of data based on filter conditions, thereby speeding up query execution.
Additionally, Parquet files contain embedded schema information, making them self-describing and capable of evolving schemas without breaking compatibility.
This flexibility is complemented by cross-platform compatibility, as Parquet files can be read and written by various big data processing frameworks, such as Apache Spark, Apache Hive, and Apache Impala, ensuring high interoperability.
Why use Parquet for LinkDB?
Given LinkDB's extensive dataset consists of over 485 million profiles, choosing the right file format is crucial for efficient data storage, processing, and analysis.
Parquet's columnar storage and compression capabilities make it an ideal choice for handling large volumes of structured data, such as the diverse range of attributes found in LinkedIn profiles. Also, Parquet's support for schema evolution simplifies data management and facilitates seamless integration with evolving data models.
The long story short is by storing LinkDB's data in the Parquet format, we ensure optimal performance and scalability for various use cases, from basic profile searches to complex analytics and machine learning tasks.
How to use LinkDB
Personally, I'm experienced with Python and prefer it, so we'll be using it in the following examples of interpreting this dataset, but of course, you could use your language of choice. Python does work pretty well for data analytics, though.
By using Python, pandas, and fastparquet, we'll have an intuitive framework for performing operations similar to those in SQL, but with more flexibility and efficiency, particularly when dealing with Parquet files.
That said, the first step in doing anything with this dataset is installing a Python integrated development environment, IDE, as well as the libraries required to interpret it.
Installing your tools
PyCharm: your Python IDE
While any integrated development environment, IDE, will work, PyCharm is my Python IDE of choice. It provides coding assistance, debugging, and many other features to make Python development easier and more efficient.
You can download it here for free (with the community edition).
Create a new project
After installing PyCharm, the next step is to create a new project and set up a virtual environment. This environment is crucial for managing project-specific dependencies without affecting other Python projects or the system-wide Python installation.
So open up PyCharm and select "File" then "New Project". Specify the project location and give your project a name.
In the new project window, ensure that the "Virtualenv" option is selected under the interpreter section. PyCharm will automatically suggest a location for the new virtual environment:
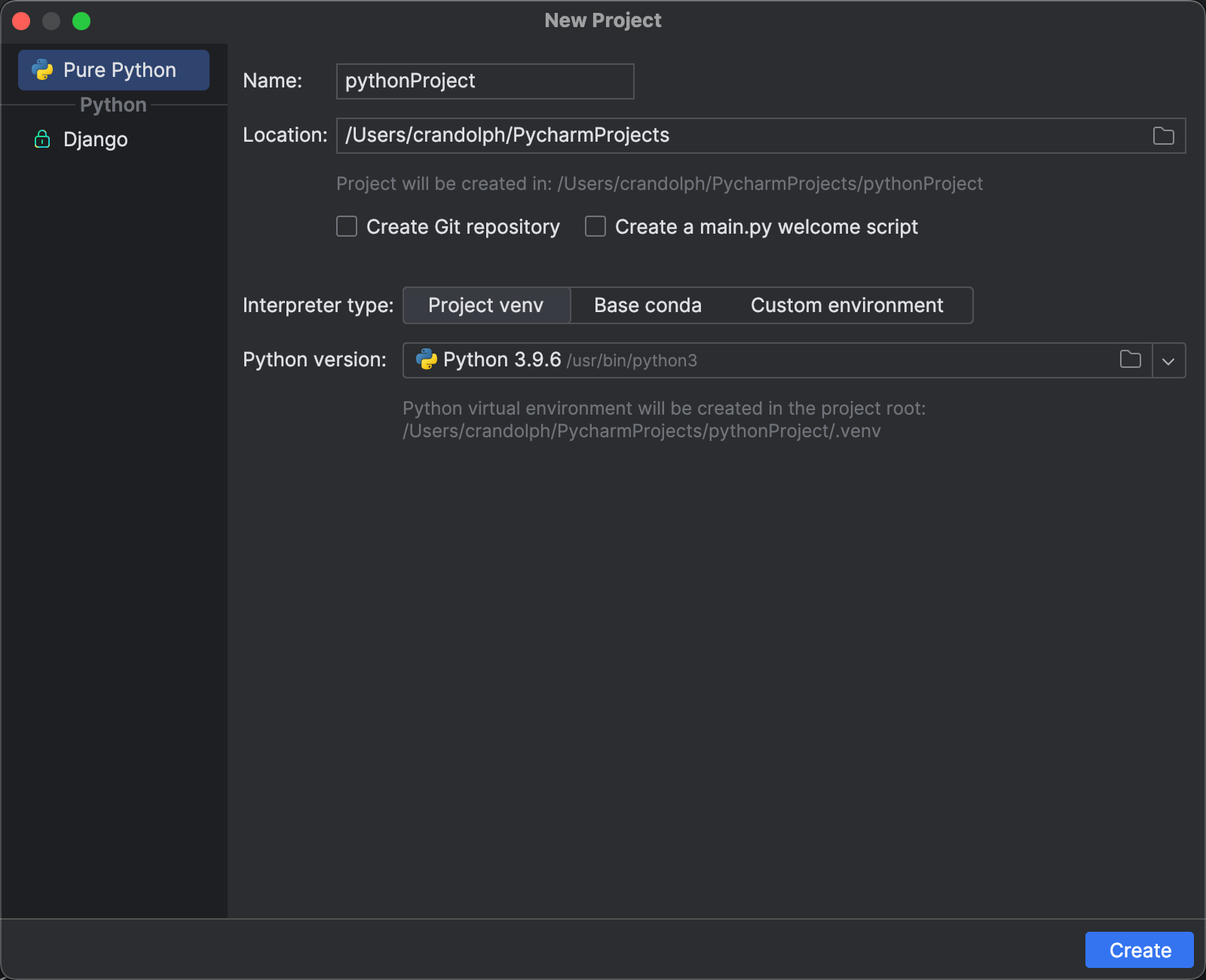
Creating a new project in PyCharm
Install pandas and fastparquet
With your project set up, you're now ready to install pandas and fastparquet. These libraries will be installed within the virtual environment you've created for your project.
You'll find the "Terminal" tab at the bottom of the PyCharm window. Click it to open the command line within PyCharm.
Then type the following command:
pip3 install pandas
And after installing pandas, you can install fastparquet by typing the following command:
pip3 install fastparquet
(Note: fastparquet might require additional dependencies like numpy and thrift. The pip install command should handle these automatically.)
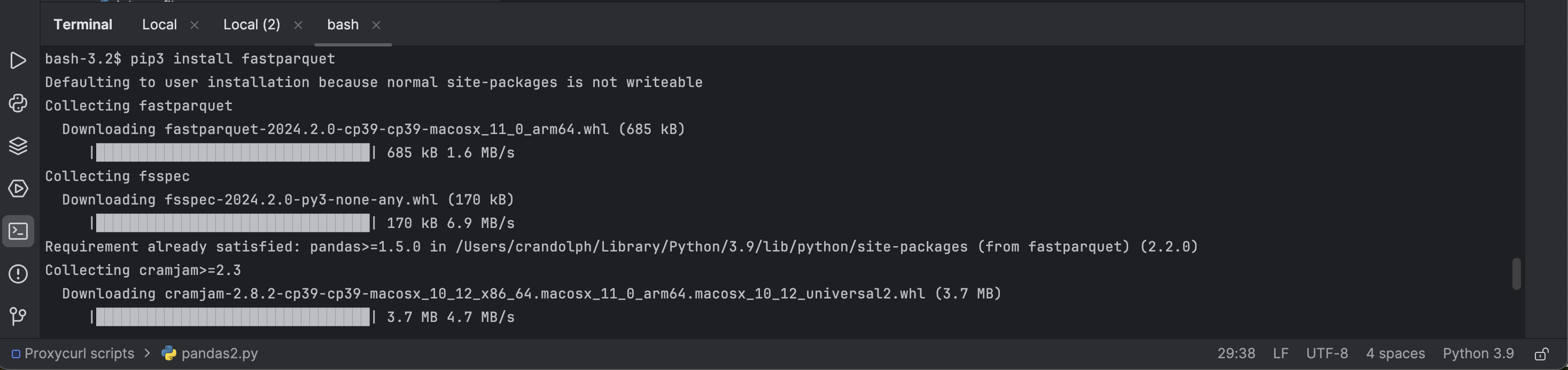
Installing fastparquet within PyCharm
Also, consider installing python-snappy. This is optional but can be beneficial for working with compressed Parquet files.
You can install it with:
pip3 install python-snappy
Verifying the installation
After installation, you can verify that pandas and fastparquet are correctly installed by importing them in a PyCharm Python file:
import pandas as pd
import fastparquet
If no errors appear, congratulations! You've successfully set up your environment to work with pandas and fastparquet in PyCharm.
Now let me show you a few examples of using and interpreting LinkDB data:
Finding and displaying LinkDB data
Consider the common task of executing a basic profile search, which in the SQL world, would involve a simple SELECT statement to fetch essential information.
In the pandas realm, this translates to reading the Parquet file into a DataFrame and selecting the required columns with just a few lines of code.
For example, using some simple Python and pandas, here's how you could load up a given Parquet file and return the list of names enclosed within:
import pandas as pd
# Load the Parquet file
df = pd.read_parquet('path_to_your_parquet_file.parquet')
# Select the first_name and last_name columns and display the first 10 rows
print(df[['first_name', 'last_name']].head(10))
That would return a result such as follows:
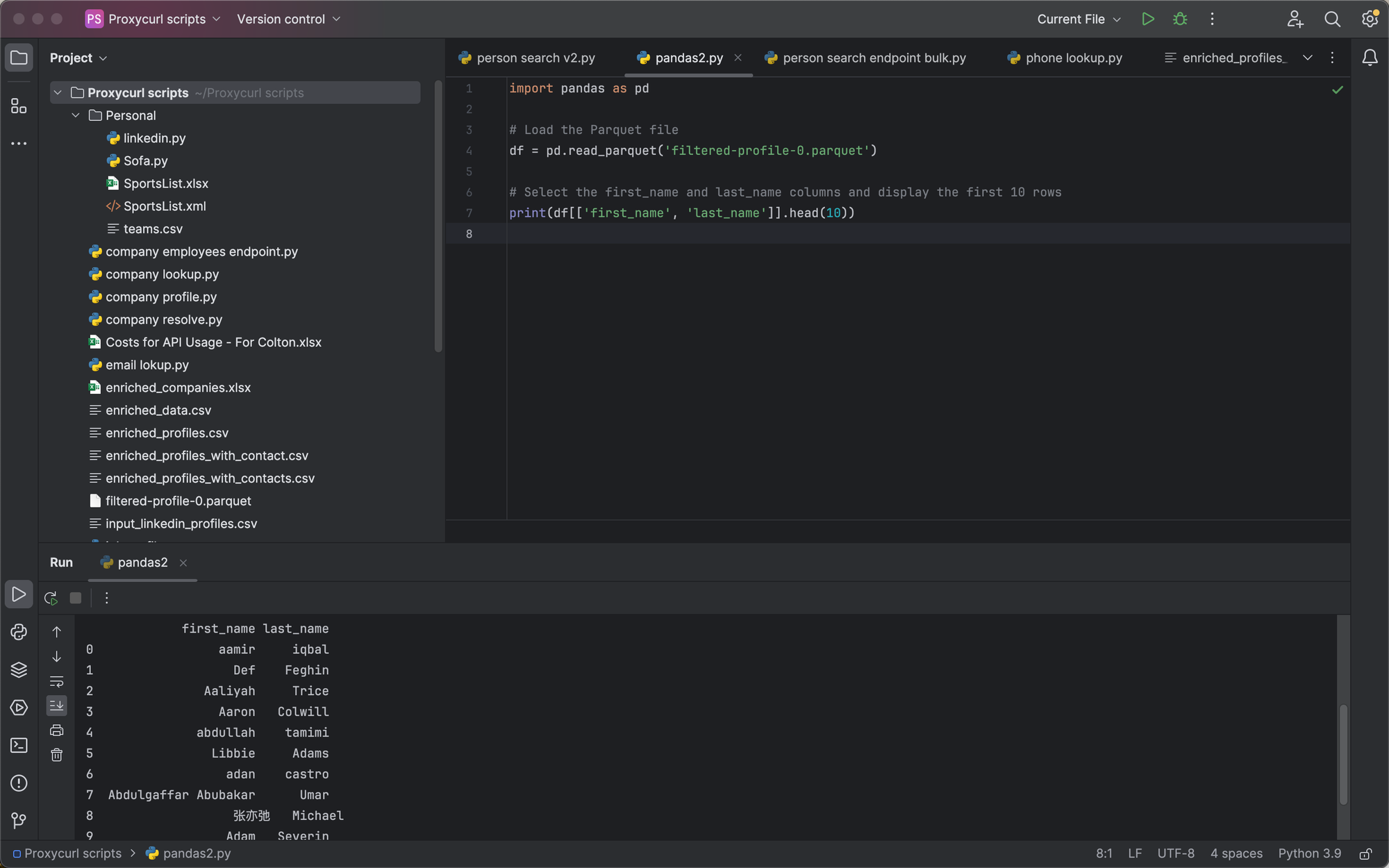
(Note: You can download this sample file above.)
We could also pull and display anything else contained in the schema above.
For example, if we edit the above script accordingly:
import pandas as pd
# Load the Parquet file
df = pd.read_parquet('filtered-profile-0.parquet')
# Adjust pandas display settings
pd.set_option('display.max_columns', None) # Ensure all columns are shown
pd.set_option('display.width', None) # Automatically adjust display width
# Select the specified columns and display the first 10 rows
columns_to_select = [
'id',
'profile_pic_url',
'first_name',
'last_name',
'city',
'country',
'headline',
'summary',
'state',
'background_cover_image_url',
'birth_date',
'connections',
'follower_count',
'occupation',
'crawler_name'
]
print(df[columns_to_select].head(10))
You'll see the following result returned instead:
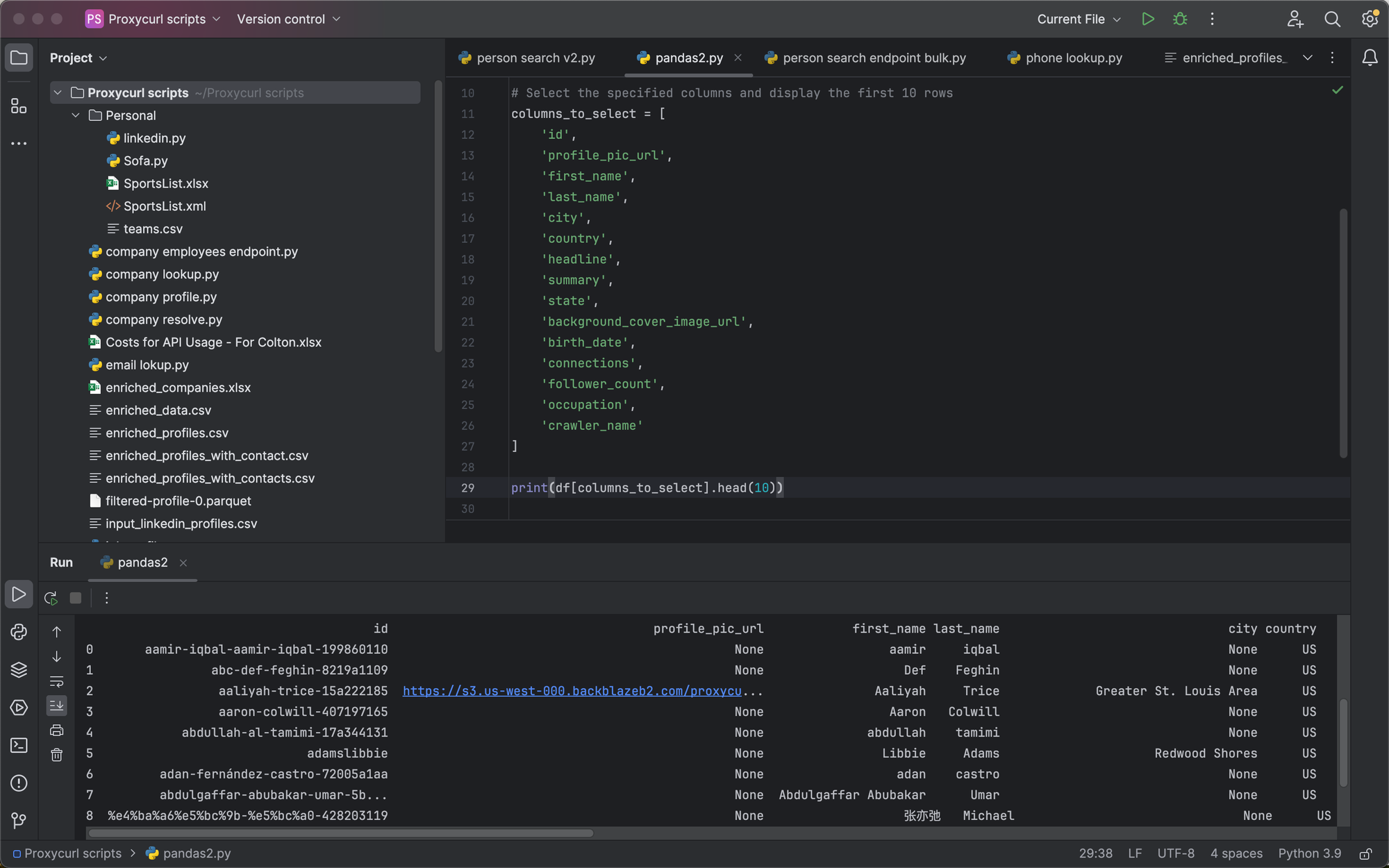
The new result with more information returned in PyCharm
The list of course keeps going, returning any of the information we have available for the requested available data points contained within the dataset.
Now let's say you work for a recruiting firm, or run a HR tech SaaS and have a specific need to query LinkDB, searching for a specific individual that fits a role.
Searching for software engineers in San Francisco
Using some Python, we can specifically target and search for variables contained in occupation and city, here's how:
import pandas as pd
# Load the Parquet file
df = pd.read_parquet('filtered-profile-0.parquet')
# Adjust pandas display settings
pd.set_option('display.max_columns', None) # Ensure all columns are shown
pd.set_option('display.width', None) # Automatically adjust display width
# Filter for software engineers in cities containing "San Francisco"
software_engineers_sf = df[df['occupation'].str.contains('Software Engineer', case=False) &
df['city'].str.contains('San Francisco', case=False)]
# Select and display the specified columns
columns_to_select = [
'first_name',
'last_name',
'occupation'
]
print(software_engineers_sf[columns_to_select])
It returns us a bunch of results of software engineers contained in San Francisco:
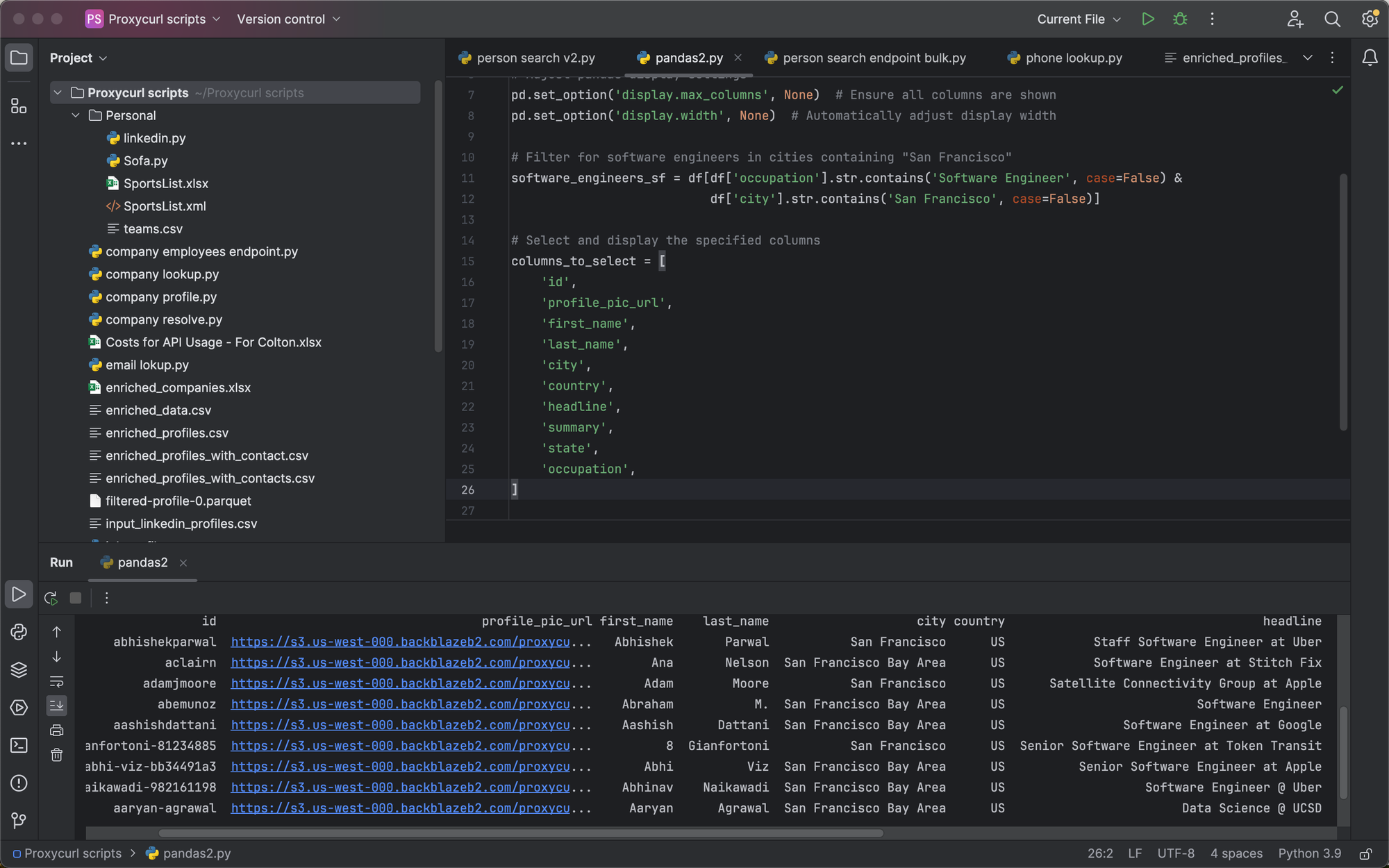
Results returned in PyCharm
Let's move onto something a little more specific:
Searching for Apple employees
LinkDB contains work experience, which is contained in filtered-profile_experience-0.parquet. Using this work experience along with the vanity IDs of any given profile, we can match these experiences to the profiles contained within filtered-profile-0.parquet.
And by doing so, we can search for interesting profiles that meet specific criteria, like working for a company.
That said, using some Python, here's how we could look for Apple employees:
import pandas as pd
# Load the profiles DataFrame from the Parquet file
profiles_df = pd.read_parquet('filtered-profile-0.parquet')
# Load the experience DataFrame from the Parquet file
experience_df = pd.read_parquet('filtered-profile_experience-0.parquet')
# Ensure both 'id' columns are strings to match correctly
profiles_df['id'] = profiles_df['id'].astype(str)
experience_df['profile_id'] = experience_df['profile_id'].astype(str)
# Check columns in both DataFrames before merging
print("Profiles DataFrame Columns:", profiles_df.columns)
print("Experience DataFrame Columns:", experience_df.columns)
# Perform the merge
merged_df = pd.merge(profiles_df, experience_df, how='inner', left_on='id', right_on='profile_id')
# Filter for Apple-related employees, excluding "Applebee's"
apple_related_employees = merged_df[
merged_df['company'].str.contains('Apple', case=False, na=False) &
~merged_df['company'].str.contains("Applebee's", case=False, na=False)
]
# Select columns to include from both original DataFrames
columns_to_include = [
'id', 'first_name', 'last_name', 'city', 'country',
'headline', 'state', 'occupation', # From profiles_df
'starts_at', 'ends_at', 'company', 'company_profile_url',
'title', 'location', 'description', # From experience_df
'profile_id', 'company_urn', 'logo_url'
]
# Ensure columns exist in merged_df before selection
final_columns = [col for col in columns_to_include if col in merged_df.columns]
final_results = apple_related_employees[final_columns]
# Display count and preview
print(f"Count: {len(final_results)}")
print(final_results.head())
# Export to CSV
final_results.to_csv('apple_related_employees_detailed.csv', index=False)
print("Export completed: 'apple_related_employees_detailed.csv'")
In the above example, the script searches for anyone that contains "Apple" in their work history, excluding the common American business named "Applebee's". If you wanted, you could also require an exact match.
You would just slightly alter the above script, such as following:
# Filter specifically for employees of Apple Inc., ensuring exact match
apple_employees = merged_df[
(merged_df['company'] == 'Apple') | (merged_df['company'] == 'Apple Inc.')
]
After the script stops searching for Apple employees, it then prints the count, displaying a sample of data, and exports it to a .csv file named apple_related_employees_detailed.csv contained within the same directory of the script.
If you wanted, you could export this to a Parquet file by editing the end:
# Export to Parquet
final_results.to_parquet('apple_employees_detailed.parquet', index=False)
print("Export completed: 'apple_employees_detailed.parquet'")
Building a web application with LinkDB
Now that you know a bit more about the logic behind searching for profiles, we can create a basic web application for searching for and exporting interesting data.
To do so, we'll use Flask, which can be installed by running pip3 install flask in PyCharm's command line.
Then create a new folder for your project to go into, and we'll need to create a few files.
First, you'll create app.py, which needs the following inside:
from flask import Flask, request, render_template, make_response
import pandas as pd
app = Flask(__name__)
# Load the DataFrames (consider doing this on demand or caching if they're large)
profiles_df = pd.read_parquet('filtered-profile-0.parquet')
experience_df = pd.read_parquet('filtered-profile_experience-0.parquet')
merged_df = pd.merge(profiles_df, experience_df, how='inner', left_on='id', right_on='profile_id')
@app.route('/', methods=['GET', 'POST'])
def index():
if request.method == 'POST':
company_name = request.form['company_name']
filtered_df = merged_df[merged_df['company'].str.contains(company_name, case=False, na=False)]
# Generate HTML table and strip leading/trailing whitespace
html_table = filtered_df.to_html(classes='data', escape=False).strip()
return render_template('results.html', tables=[html_table], titles=filtered_df.columns.values, company_name=company_name)
return render_template('index.html')
@app.route('/export/<company_name>', methods=['GET'])
def export(company_name):
filtered_df = merged_df[merged_df['company'].str.contains(company_name, case=False, na=False)]
# Clean each string column in the DataFrame before exporting
for column in filtered_df.columns:
if filtered_df[column].dtype == 'object':
filtered_df[column] = filtered_df[column].apply(
lambda x: x.replace('\n', '').replace("'", '') if isinstance(x, str) else x)
csv = filtered_df.to_csv(index=False)
response = make_response(csv)
response.headers['Content-Disposition'] = f'attachment; filename={company_name}_employees.csv'
response.headers['Content-Type'] = 'text/csv'
return response
if __name__ == '__main__':
app.run(debug=True)
Then within that same folder, create another folder named templates and create two new .html files within it, the first being named index.html:
<!DOCTYPE html>
<html>
<head>
<title>Company Search</title>
</head>
<body>
<h2>Search for Company Employees</h2>
<form method="post">
<input type="text" name="company_name" placeholder="Enter Company Name">
<input type="submit" value="Search">
</form>
</body>
</html>
And the second being named results.html:
<!DOCTYPE html>
<html>
<head>
<title>Search Results</title>
<style>
table {
width: 100%;
border-collapse: collapse;
}
th, td {
border: 1px solid #ddd;
padding: 8px;
text-align: left;
}
th {
background-color: #f2f2f2;
}
tr:nth-child(even){background-color: #f9f9f9;}
.button {
display: inline-block;
padding: 10px 20px;
font-size: 16px;
cursor: pointer;
text-align: center;
text-decoration: none;
color: #fff;
background-color: #007bff;
border: none;
border-radius: 5px;
}
.button:hover {
background-color: #0056b3;
}
</style>
</head>
<body>
<h2>Search Results for "{{ company_name }}"</h2>
{% if tables %}
<div>{{ tables|safe }}</div>
<!-- Convert link to button -->
<a href="{{ url_for('export', company_name=company_name) }}" class="button">Export to CSV</a>
{% else %}
<p>No results found.</p>
{% endif %}
<br>
<br>
<!-- Convert link to button for consistency, if desired -->
<a href="/" class="button">New Search</a>
</body>
</html>
Finally, move your two Parquet files filtered-profile-0.parquet and filtered-profile_experience-0.parquet into the same folder as app.py is contained in, as we'll use these as our database, and then right click app.py within PyCharm and click "Run".
Then visit http://127.0.0.1:5000/ within your browser:

One final note
If you landed on this post looking for a current product rather than historical context, LinkDB is no longer the thing to buy. This post explains what LinkDB was and how to work with a large LinkedIn-derived dataset, but Proxycurl and LinkDB themselves have been sunset.
What I am building now is NinjaPear, which takes a different path. Instead of continuing down the old LinkedIn dataset route, NinjaPear is the newer B2B intelligence platform we are focused on today.
I am keeping this article live because the technical bits, Parquet discussion, schema examples, and sample Python workflows are still useful if you're evaluating this category or working with historical exports.
If your actual need today is fresh company or people intelligence from public web sources, start with NinjaPear instead.
