
How to list all employees of any company
I receive a lot of requests seeking for help in listing employees of companies. Which is why I am happy to share that the Employee Listing Endpoint is generally available on Proxycurl API today!
It is not easy to launch this endpoint because no publicly available Professional Social Network page lists all employees. Without a focused page to page, the only way forward is to scrape every (person) profile. That is what we did.
Yes, to launch the Employee Listing Endpoint, we had to:
- Scrape every person profile
- Implement infrastructure to keep profiles up to date
That brings me to the next point -- how else can you get a list of all employees other than Proxycurl's Employee Listing API Endpoint?
Use Professional Social Network to list employees
Given that we scrape Professional Social Network public profiles to power the Proxycurl's Employee Listing Endpoint, it is only natural that Professional Social Network, the canonical source of these data should be the best way forward to get employee listing data, And for the most part, that is true.
There are two "buts".
- It is non-trivial to scrape Professional Social Network as a logged-in user at scale. It is also not legal.
- You are capped at 1000 results per company.
I tried to list all 235,789 employees of Apple.
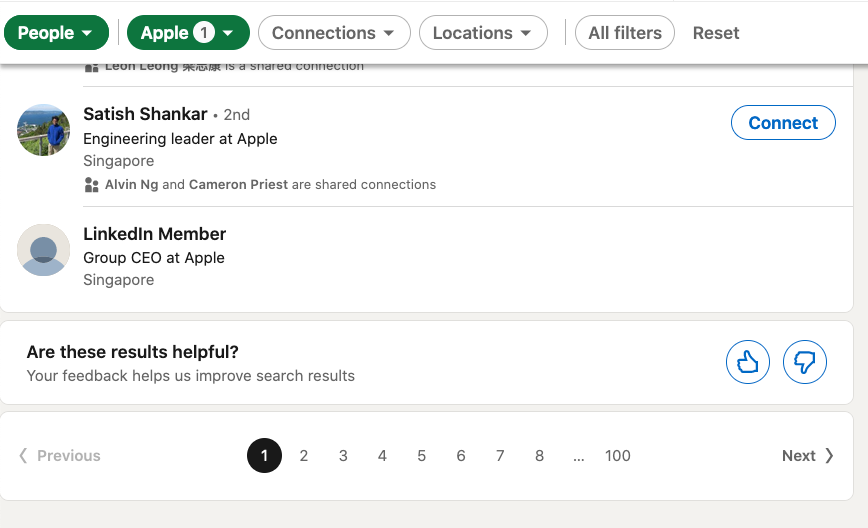
So, Professional Social Network works if you do not mind scraping Professional Social Network with an active login session, abiding by their rate limits and their 1000 profile limit.
Use LinkDB to list employees
LinkDB is our publicly accessible PostgreSQL database populated with people and company profiles.
Before the launch of our Employee Listing API endpoint, I usually shepherd inquiries on the employee listing problem to LinkDB. And yes, you can use LinkDB to list employees and perform very complex queries! I recommend LinkDB if you are looking to perform a complex search such as:
Find me all
- who have left Apple in the last 3 months
- who is a Software Engineer
- And for the simple use case of listing employees, this is the SQL query you can run on LinkDB to get a list of active employees of DigitalOcean.
And this is the SQL query I can run on LinkDB to get results for the complex search above.
SELECT profile_experience.profile_id, profile.first_name, profile.last_name, profile_experience.title
FROM profile_experience
JOIN profile ON profile_experience.profile_id = profile.id
WHERE profile_experience.company_profile_url= 'https://www.professionalsocialnetwork.com/company/digitalocean'
AND profile_experience.ends_at IS NULL
However, the caveats of LinkDB remains true:
- You have to be comfortable with writing SQL. We do not provide support with programming (or writing SQL queries)
- LinkDB is beta software, and will likely remain so in perpetuity.
- Performance is not guaranteed and we do not offer the service of optimizing LinkDB for customers' (arbitrary) queries.
Use Proxycurl's Employee Listing Endpoint
I will not use LinkDB in my user-facing product. But I will integrate Proxycurl's Employee Listing Endpoint into my product because it checks the following criteria
Proxycurl's Employee Listing Endpoint is
- highly-available
- predictable (and fast) response
- consistent in performance
- predictable pricing
With the endpoint, you can list
- past employees
- present employees
- both
All you need is a Professional Social Network Company Profile URL. Given that Proxycurl is a developer-tool product, let's dive into code. Let's get a list of Clearbit's employees.
Counting Clearbit employees
from pprint import pprint
import requests
api_key = 'YOUR_PROXYCURL_API_KEY'
host = 'https://nubela.co/proxycurl'
api_endpoint = f'{host}/api/Professional Social Network/company/employees/count'
header_dic = {'Authorization': 'Bearer ' + api_key}
response = requests.get(api_endpoint,
params={
'url': f'https://www.professionalsocialnetwork.com/company/clearbit',
},
headers=header_dic)
pprint(response.json())
Proxycurl returns 69 active employees.
$ time python employeelisting.py
200
{"total_employee": 69}
real 0m1.814s
user 0m0.176s
sys 0m0.051s
The endpoint takes 1.8s to complete.
But who exactly are the employees?
Let's make another API call, but this time to the /proxycurl/api/Professional Social Network/company/employees/count endpoint
from pprint import pprint
import requests
api_key = 'YOUR_PROXYCURL_API_KEY'
host = 'https://nubela.co/proxycurl'
api_endpoint = f'{host}/api/Professional Social Network/company/employees/'
header_dic = {'Authorization': 'Bearer ' + api_key}
response = requests.get(api_endpoint,
params={
'url': f'https://www.professionalsocialnetwork.com/company/clearbit',
},
headers=header_dic)
pprint(response.json())
Here are the results, 69 Professional Social Network Profiles (truncated).
$ time python employeelisting2.py
{'employees': [{'profile_url': 'https://www.professionalsocialnetwork.com/in/scott-carter-742a876'},
{'profile_url': 'https://www.professionalsocialnetwork.com/in/adamrutkow'},
{'profile_url': 'https://www.professionalsocialnetwork.com/in/jared-j-chan-%E2%98%81%EF%B8%8F-31b81273'},
{'profile_url': 'https://www.professionalsocialnetwork.com/in/asiqur-anik'},
{'profile_url': 'https://www.professionalsocialnetwork.com/in/jasmine-sabba-b4741329'},
{'profile_url': 'https://www.professionalsocialnetwork.com/in/bradylemmerman'},
{'profile_url': 'https://www.professionalsocialnetwork.com/in/ashannetaylor'},
{'profile_url': 'https://www.professionalsocialnetwork.com/in/ethanhackett'},
{'profile_url': 'https://www.professionalsocialnetwork.com/in/neil-bartholomay'},
{'profile_url': 'https://www.professionalsocialnetwork.com/in/colbyaley'},
{'profile_url': 'https://www.professionalsocialnetwork.com/in/djlumley'},
{'profile_url': 'https://www.professionalsocialnetwork.com/in/rossmoser'},
...]}
real 0m1.010s
user 0m0.164s
sys 0m0.047s
The endpoint takes 1s to complete.
Professional Social Network says that Clearbit has 108 employees. We have 63 of them. This is expected because
- We scrape US Profile only. If Proxycurl have employees outside of the US region, our API will not be able to return them.
- Not all Professional Social Network profiles have public profiles. We can only return public profile results.
Counting Clearbit employees
from pprint import pprint
import requests
api_key = 'YOUR_PROXYCURL_API_KEY'
host = 'https://nubela.co/proxycurl'
api_endpoint = f'{host}/api/Professional Social Network/company/employees/count'
header_dic = {'Authorization': 'Bearer ' + api_key}
response = requests.get(api_endpoint,
params={
'url': f'https://www.professionalsocialnetwork.com/company/clearbit',
},
headers=header_dic)
pprint(response.json())
Proxycurl returns 69 active employees.
$ time python employeelisting.py
200
{"total_employee": 69}
real 0m1.814s
user 0m0.176s
sys 0m0.051s
The endpoint takes 1.8s to complete.
But who exactly are the employees?
Let's make another API call, but this time to the /proxycurl/api/Professional Social Network/company/employees/count endpoint
from pprint import pprint
import requests
api_key = 'YOUR_PROXYCURL_API_KEY'
host = 'https://nubela.co/proxycurl'
api_endpoint = f'{host}/api/Professional Social Network/company/employees/'
header_dic = {'Authorization': 'Bearer ' + api_key}
response = requests.get(api_endpoint,
params={
'url': f'https://www.professionalsocialnetwork.com/company/clearbit',
},
headers=header_dic)
pprint(response.json())
Here are the results, 69 Professional Social Network Profiles (truncated).
$ time python employeelisting2.py
{'employees': [{'profile_url': 'https://www.professionalsocialnetwork.com/in/scott-carter-742a876'},
{'profile_url': 'https://www.professionalsocialnetwork.com/in/adamrutkow'},
{'profile_url': 'https://www.professionalsocialnetwork.com/in/jared-j-chan-%E2%98%81%EF%B8%8F-31b81273'},
{'profile_url': 'https://www.professionalsocialnetwork.com/in/asiqur-anik'},
{'profile_url': 'https://www.professionalsocialnetwork.com/in/jasmine-sabba-b4741329'},
{'profile_url': 'https://www.professionalsocialnetwork.com/in/bradylemmerman'},
{'profile_url': 'https://www.professionalsocialnetwork.com/in/ashannetaylor'},
{'profile_url': 'https://www.professionalsocialnetwork.com/in/ethanhackett'},
{'profile_url': 'https://www.professionalsocialnetwork.com/in/neil-bartholomay'},
{'profile_url': 'https://www.professionalsocialnetwork.com/in/colbyaley'},
{'profile_url': 'https://www.professionalsocialnetwork.com/in/djlumley'},
{'profile_url': 'https://www.professionalsocialnetwork.com/in/rossmoser'},
...]}
real 0m1.010s
user 0m0.164s
sys 0m0.047s
The endpoint takes 1s to complete.
Professional Social Network says that Clearbit has 108 employees. We have 63 of them. This is expected because
- We scrape US Profile only. If Proxycurl have employees outside of the US region, our API will not be able to return them.
- Not all Professional Social Network profiles have public profiles. We can only return public profile results.
We recommend that you use Proxycurl's Employee Listing Endpoint for just US region only
Remember how earlier in the article, I mentioned that the only way we can support the Employee Listing Endpoint is by crawling all profiles in a region. It turns out that we do have limited crawling capacity. Just to give you a sense of what limited means to us. We are talking about scraping millions of profiles a day.
It takes a lot of resources to
- Surface all Professional Social Network profiles of a region
- And KEEP them refreshed as best as we can
As such, we have to limit the Employee Listing Endpoint to the US region only. (It does work internationally, but we do not offer any guarantees on the quality of the results.)
How much does Proxycurl's Employee Listing endpoint cost?
- The Employee Listing endpoint costs 5 credits per employee returned.
- The minimum cost of this endpoint is 10 credits.
- The Employee Listing Count endpoint costs 10 credits per call.
Get started with Proxycurl's Employee Listing endpoint today!
You can view the documentation for the
- Employee Listing endpoint at https://nubela.co/proxycurl/docs#company-api-employee-listing-endpoint
- Employee Listing Count endpoint at https://nubela.co/proxycurl/docs#company-api-employee-count-endpoint
Do give it a spin and if you have any questions, you can always talk to me at [email protected] . I look forward to your emails and I do reply promptly :)
Stay in the loop with Proxycurl's product updates:
Proxycurl ships data-driven developer tools so you can build awesome data-driven products without the need for a data-acquisition team. The Proxycurl roadmap is packed full for the next 12 months and as much as I want to tell you all about it, but developers (like us) make very poor timeline estimates. So I avoid sharing anything until it is coming soon or already live.
But if there is anything consistent about us, is that we always deliver. Click here to subscribe and stay in the loop with Proxycurl's product updates!