
How To Build A Crunchbase Scraper In 2025 - With Code Demo
In a time where data is worth its weight in gold, Crunchbase is a goldmine. It’s home to thousands of company profiles, their investment data, leadership position, funding information, news and much more. Crunchbase scraping will allow you to get to the gold chunks (the insights you need) and filter out all the debris (all the other information irrelevant to you).
In this article, we’ll walk you through the process of building a Crunchbase scraper from scratch, including all the technical details and code using Python, with a working demo for you to follow along. With that being said, you should also understand that building a Crunchbase scraper is a time consuming task, with many challenges along the way. That is why we will also go through a demo of an alternative approach using Proxycurl, a paid API-based tool that does the work for you. With both options on the table, you can weigh their advantages and choose the one that best fits your needs.
Here’s a sneak peak at a basic Crunchbase scraper using Python to extract company name and headquarter city from the website.
import requests
from bs4 import BeautifulSoup
url = 'https://www.crunchbase.com/organization/apple'
headers = {'User-Agent': 'Mozilla/5.0'}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.content, 'html.parser')
name_section = soup.find('h1', class_='profile-name')
company_name = name_section.get_text(strip=True) if name_section else 'N/A'
headquarters_section = soup.find('span', class_='component--field-formatter field_type_text')
headquarters_city = headquarters_section.get_text(strip=True) if headquarters_section else 'N/A'
print(f"Company Name: {company_name}")
print(f"Headquarters City: {headquarters_city}")
Now, to our alternative approach, Proxycurl. It is a comparably efficient Crunchbase scraping tool and you can pull the same company information using just a few lines of code. The added benefit here is you won’t have to worry about HTML parsing or any scraping roadblocks with Proxycurl.
import requests
api_key = 'YOUR_API_KEY'
headers = {'Authorization': 'Bearer ' + api_key}
api_endpoint = 'https://nubela.co/proxycurl/api/Professional Social Network/company'
params = {
'url': 'https://www.professionalsocialnetwork.com/company/apple/',
}
response = requests.get(api_endpoint, params=params, headers=headers)
data = response.json()
print(f"Company Name: {data['company_name']}")
print(f"Company Headquarter: {data['hq']['city']}")
By the end of this article, you'll be familiar with both methods and be able to make an informed decision. So whether you're excited to roll up your sleeves and code your own scraper or you’re after a one stop solution, keep reading to set up your Crunchbase scraper.
Building your Crunchbase Scraper from scratch
Crunchbase contains several data types including acquisitions, people, events, hubs and funding rounds. For this article, we will go through building a simple Crunchbase scraper to parse out a company's description to retrieve as JSON data. Let’s go with Apple for our example.
First, we will need to define a function to extract the company description. The get_company_description() function searches for the span HTML element that contains the company’s description. It then extracts the text and returns it:
def get_company_description(raw_html):
description_section = raw_html.find("span", {"class": "description"})
return description_section.get_text(strip=True) if description_section else "Description not found"
This sends an HTTP GET request to the URL of the company profile you want to scrape, in this case, Apple’s profile. Here’s what the full code looks like:
import requests
from bs4 import BeautifulSoup
def get_company_description(raw_html):
# Locate the description section in the HTML
description_section = raw_html.find("span", {"class": "description"})
# Return the text if found, else return a default message
return description_section.get_text(strip=True) if description_section else "Description not found"
# URL of the Crunchbase profile to scrape
url = "https://www.crunchbase.com/organization/apple"
# Set the User-Agent header to simulate a browser request
headers = {"User-Agent": "Mozilla/5.0"}
# Send a GET request to the specified URL
response = requests.get(url, headers=headers)
# Check if the request was successful (status code 200)
if response.status_code == 200:
# Parse the HTML content of the response using BeautifulSoup
soup = BeautifulSoup(response.content, "html.parser")
# Call the function to get the company description
company_description = get_company_description(soup)
# Print the retrieved company description
print(f"Company Description: {company_description}")
else:
# Print an error message if the request failed
print(f"Failed to retrieve data. Status Code: {response.status_code}")
This script does the trick for pulling Apple’s company description from Crunchbase. Depending on your experience and what you are looking for, things can get a lot trickier. Handling large volumes of data, managing pagination, bypassing authwall mechanisms, there are a lot of hurdles along the way. Keep in mind that you will have to:
- Perform this action for every single field you’re interested in.
- Stay updated with any modifications in the web page. Even a small change in how a field is presented in the website can result in a minor or a significant tweak in the scraping logic.
Note: Check the website’s terms of service and robots.txt file to ensure you're scraping responsibly and within legal limits.
Why is building a Crunchbase Scraper challenging?
Building your own Crunchbase scraper is a viable option, but before you go Gung-ho, be aware of what challenges await you.
Accuracy and completeness
Your efforts will be meaningless if the extracted data is false. Manually scraping raises the margin of error, and the code may overlook important data if the page doesn't fully load or if some content is embedded in iframes or external resources.
Crunchbase's structure and changes
Parsing the HTML of a webpage to extract specific data fields is a basic step in scraping. Crunchbase's HTML is complex, with dynamic elements and multiple layers of containers. It is a task in itself to identify and target the right data. This added with the website’s changing structure can make your job tenfold tougher.
Handling authwalls and anti-scraping mechanisms
Crunchbase protects most of their data behind an authwall and will require login credentials or a premium account. Handling login sessions, tokens, or cookies in the scraper manually makes the task more complex, especially for maintaining these sessions across multiple requests. Similarly, Crunchbase uses bot detection systems and rate-limits requests. You run a risk of getting blocked, and bypassing these protections means implementing techniques such as rotating proxies or handling CAPTCHAs, which is easier said than done.
Building your own Crunchbase scraper gives you flexibility and a sense of accomplishment, but weigh that against the challenges involved. It demands deep technical expertise, constant monitoring and effort to get the data you want. This is without mentioning how time-consuming and prone to errors the process can be. Consider whether the effort and maintenance are truly worth it for your needs.
The hassle-free way to set up a Crunchbase Scraper
Phew! Building your Crunchbase Scraper from scratch sure is some serious work. Not only do you have to dedicate a lot of your time and effort, but also keep an eye out for potential challenges. Thank god Proxycurl exists!
Take advantage of Proxycurl’s endpoints and get all the data you could ever wish for in JSON format. And since Crunchbase only provides public data available on the company, there is no data out of your reach. Any private information scraping attempt will result in 404. Rest assured, you will never be charged for a request that returns an error code.
Proxycurl provides you with a list of standard fields under the Company Profile Endpoint. You can see a full example of any response in the documentation on the right-hand side below the request that generated it. Proxycurl has the ability to scrape the following fields at your request:
categoriesfunding_dataexit_dataacquisitionsextra
Each of these fields that you request comes at an additional credit cost, so choose only the parameters you require. But when you do need them, Proxycurl puts them a single parameter away!
Now that we are familiar with Proxycurl, let's walk through a working demo. We'll include two examples, for Postman and then for Python.
Crunchbase scraping with Proxycurl via Postman
Step 1: Set up your account and get your API key
Create an account with Proxycurl and you’ll be assigned with a unique API key. Proxycurl is a paid API, and you would need to authenticate every request with a bearer token (your API key). You will also receive 100 credits if you signed up with your work email, 10 credits if you used personal email. Then you can start experimenting immediately! Here’s what your dashboard should look like.
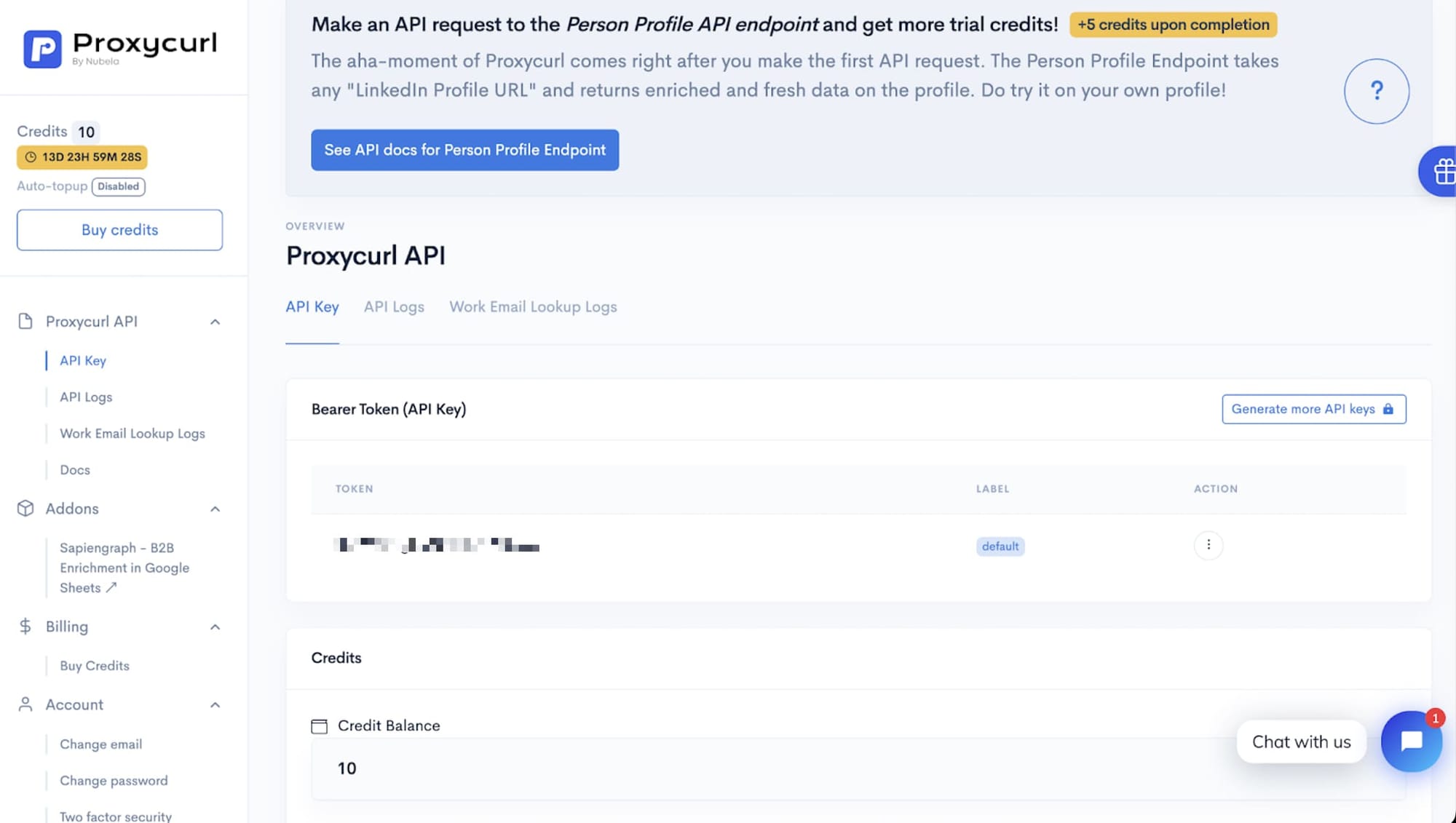
From here, you can scroll down and choose to work with Person Profile Endpoint or the Company Profile Endpoint. The Person Profile Endpoint is a useful tool if you're looking to scrape Professional Social Network. Check out [How to Build a Professional Social Network Data Scraper](https://nubela.co/blog/how-to-build-a-Professional Social Network-data-scraper/) for further details.
For this use case, we’ll just be working with the Company Profile Endpoint.
Step 2: Run Postman and set your bearer token
Go to Proxycurl's collection in Postman, click on the Company Profile Endpoint doc and find the orange button that says "Run in Postman" and click it. Then click "Fork Collection" and log in however you like. It should look something like this. We have a full tutorial on how to set up Proxycurl API in Postman.
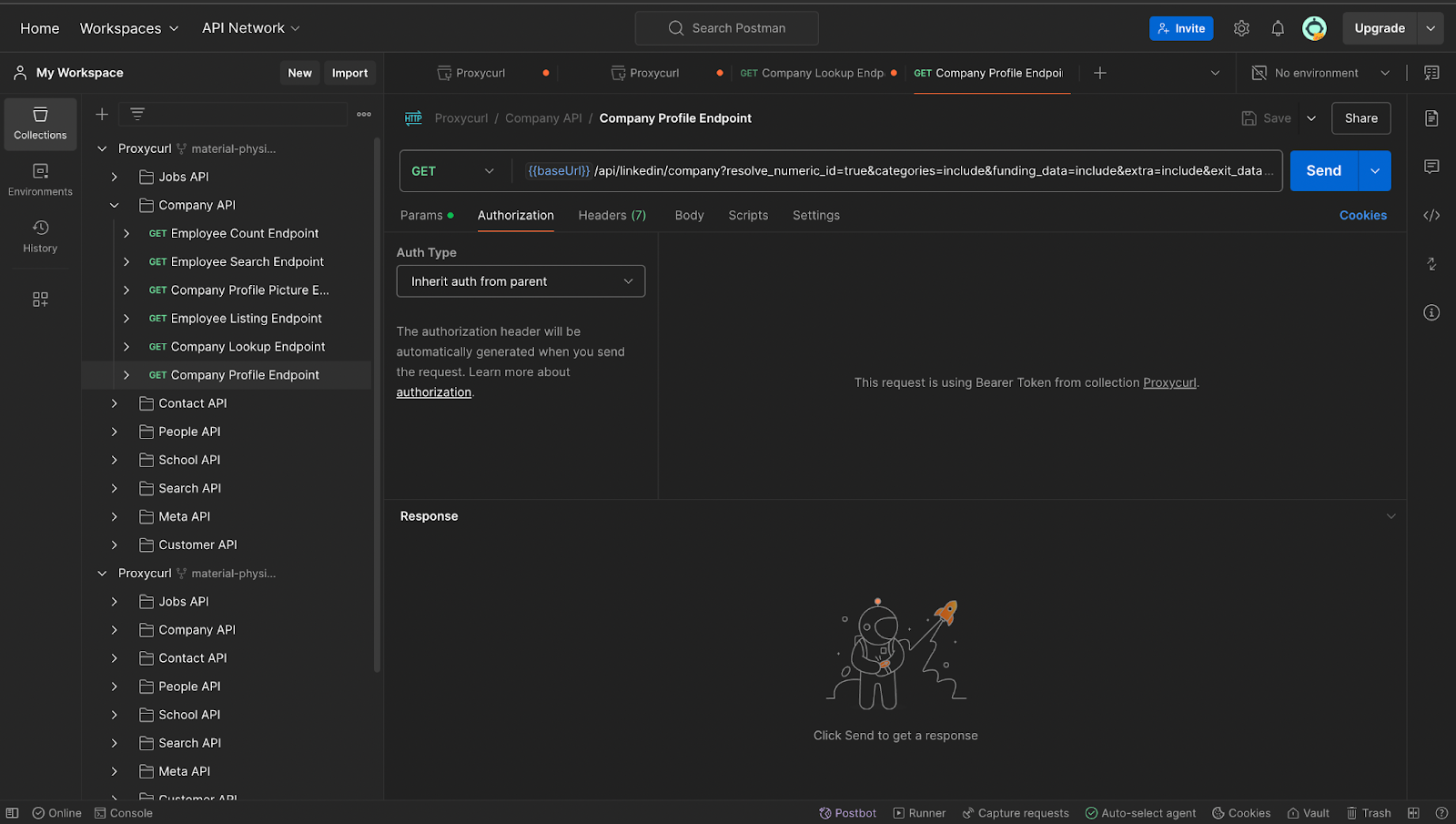
Once you’re in Postman, go to Authorization, choose Bearer Token and add your token (your API Key) and limit it to Proxycurl. You can do this from the Variables tab or from the pop-up that appears when you start typing into the "Token" field. Name the token to your liking, or just go with the name, Bearer Token.
Verify that the Authorization type is set to "Bearer Token" and that you have typed {{Bearer Token}} into the Token field and click Save in the upper right-hand corner. Remember to click Save!! Your page should look like this:
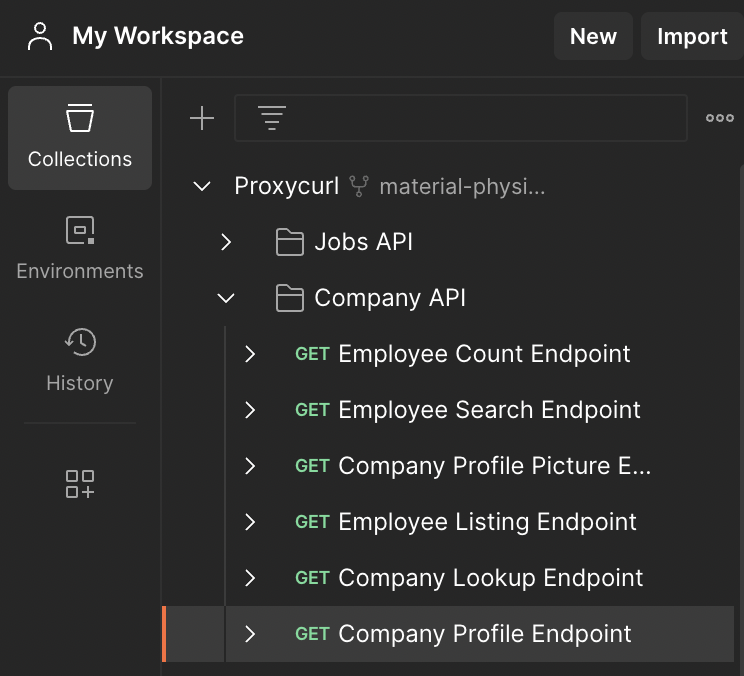
Step 3: Navigate to your workspace
On the left-hand side, under "My workspace", go to your Proxycurl collection and then the Company API. You will find a list of options on the dropdown menu, but here’s what you will need to know:
- Company Profile Endpoint: Enriches company profile with Crunchbase data like funding, acquisitions, etc. You will need to use the company’s Professional Social Network profile URL as input parameter to the API.
- Company Lookup Endpoint: Input a company’s website and get its Professional Social Network URL.
- Company Search Endpoint: Input various search parameters and find a list of companies that matches that search criteria, and then pull Crunchbase data for these companies.
Step 4: Edit your params and send!
Go to Company Profile Endpoint and from there, you can uncheck some of the fields if you want or modify others. For instance, you might want to change use_cache from if-present to if-recent to get the most up-to-date info, but maybe you don't need the acquisitions information this time.
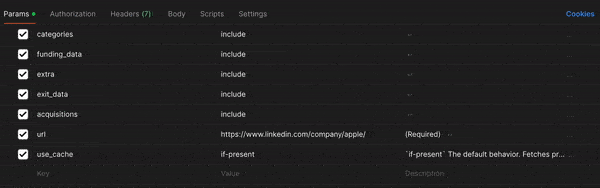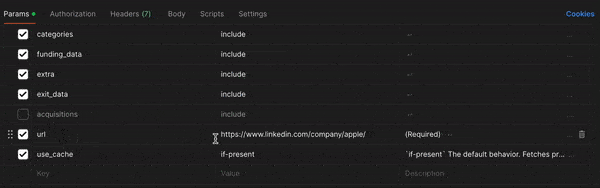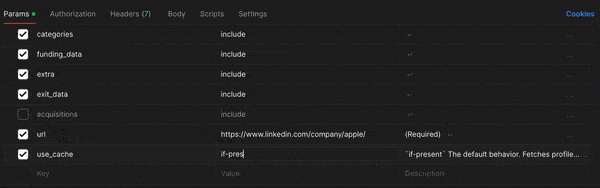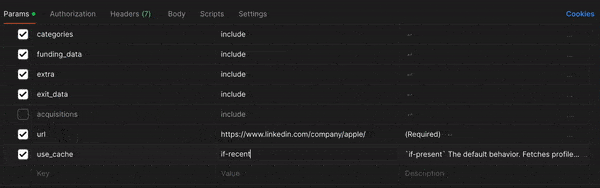
Once you've modified all the fields to your liking, click the blue "Send" button in the upper left-hand corner. Your output should look something like this.
If you come across a 401 status code, it is most likely you forgot to hit Save after setting the Authorization type to {{Bearer Token}} in Step 2. A good way to troubleshoot this is to see if you can fix it by editing the Authorization tab for this specific query to be the {{Bearer Token}} variable. If that fixes it, then the auth inheritance isn't working, which probably means you forgot to save.
Crunchbase scraping with Proxycurl via Python
Now let’s try and do the same with Python. In the Proxycurl docs under Company Profile Endpoint, you can toggle between shell and Python. We’ll use the company endpoint to pull Crunchbase-related data, and it’s as simple as switching to Python in the API docs.
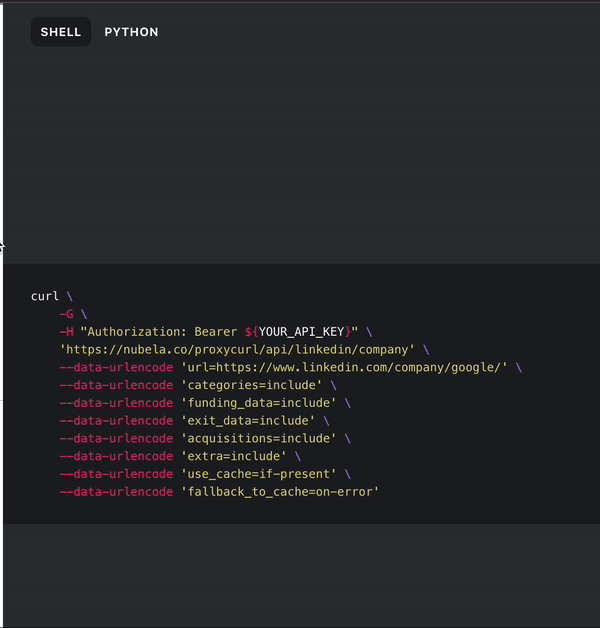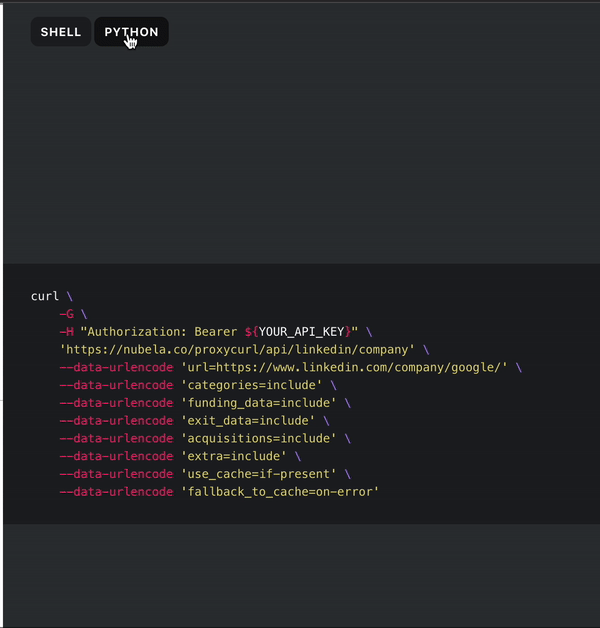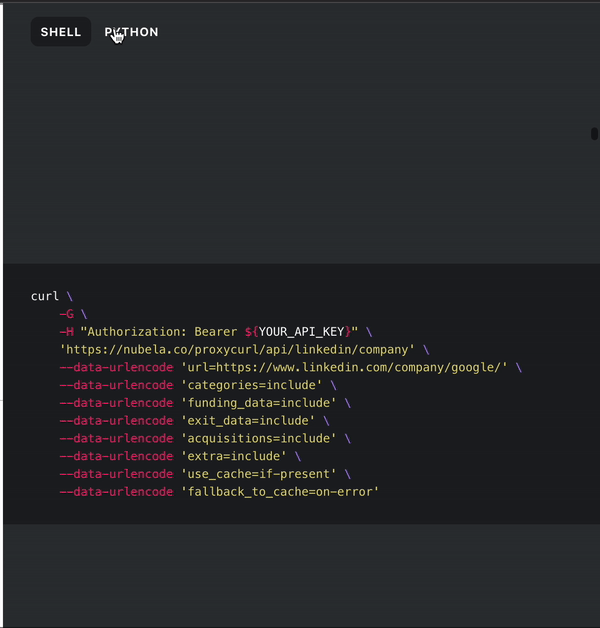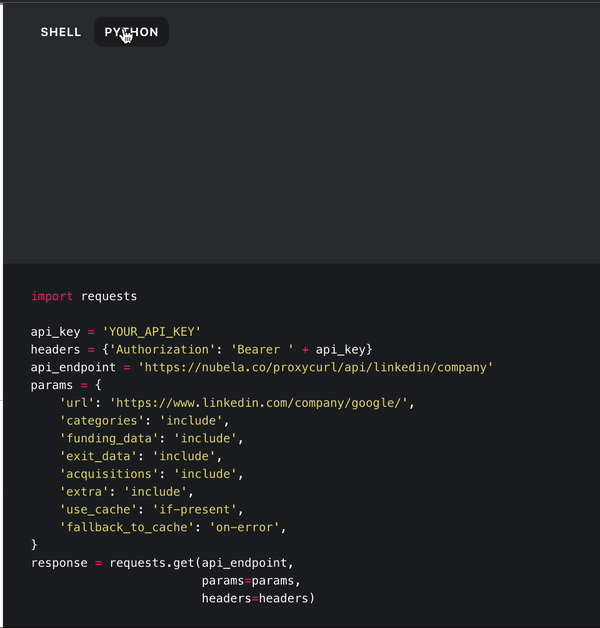
Now, we can paste in our API key where it says YOUR_API_KEY. Once we have everything set up, we can extract the JSON response and print it. Here’s the code for that, and you can make changes to it as needed:
import requests
api_key = 'YOUR_API_KEY'
headers = {'Authorization': 'Bearer ' + api_key}
api_endpoint = 'https://nubela.co/proxycurl/api/Professional Social Network/company'
params = {
'url': 'https://www.professionalsocialnetwork.com/company/apple/',
'categories': 'include',
'funding_data': 'include',
'exit_data': 'include',
'acquisitions': 'include',
'extra': 'include',
'use_cache': 'if-present',
'fallback_to_cache': 'on-error',
}
response = requests.get(api_endpoint, params=params, headers=headers)
print(response.json())
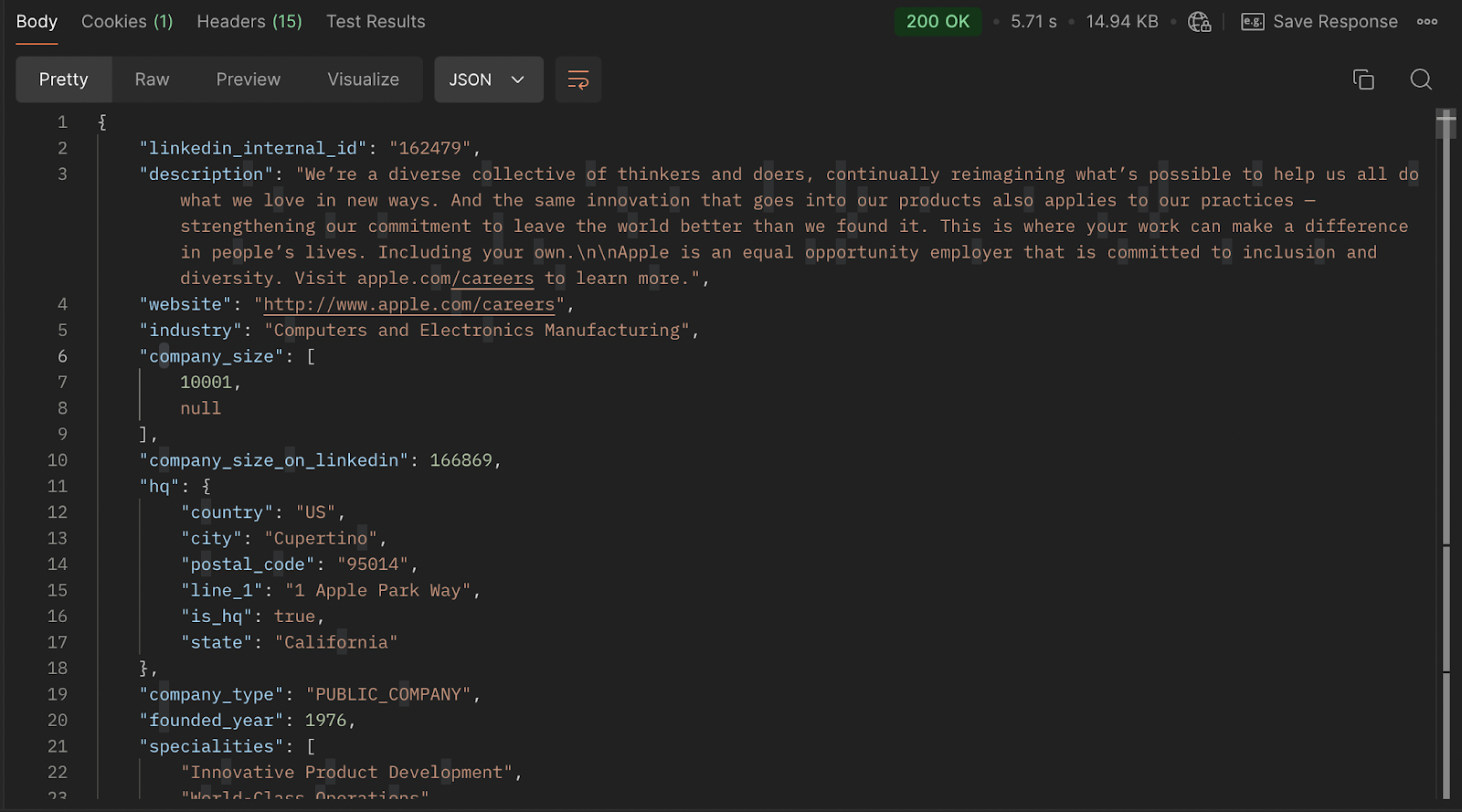
Now, what you get is a structured JSON response that includes all the fields that you have specified. Something like this:
"Professional Social Network_internal_id": "162479",
"description": "We're a diverse collective of thinkers and doers, continually reimagining what's possible to help us all do what we love in new ways. And the same innovation that goes into our products also applies to our practices -- strengthening our commitment to leave the world better than we found it. This is where your work can make a difference in people's lives. Including your own.\n\nApple is an equal opportunity employer that is committed to inclusion and diversity. Visit apple.com/careers to learn more.",
"website": "http://www.apple.com/careers",
"industry": "Computers and Electronics Manufacturing",
"company_size": [
10001,
null
],
"company_size_on_Professional Social Network": 166869,
"hq": {
"country": "US",
"city": "Cupertino",
"postal_code": "95014",
"line_1": "1 Apple Park Way",
"is_hq": true,
"state": "California"
},
"company_type": "PUBLIC_COMPANY",
"founded_year": 1976,
"specialities": [
"Innovative Product Development",
"World-Class Operations",
"Retail",
"Telephone Support"
],
"locations": [
{
"country": "US",
"city": "Cupertino",
"postal_code": "95014",
"line_1": "1 Apple Park Way",
"is_hq": true,
"state": "California"
}
]
...... //Remaining Data
}
Great! Congratulations on your journey from zero to data!
Is any of this legal?
Yes, scraping Crunchbase is legal. The legality of scraping is based on different factors like the type of data, the website’s terms of service, data protection laws like GDPR, and much more. The idea is to scrape for publicly available data within these boundaries. Since Crunchbase only houses public data, it is absolutely legal to scrape by operating within the Crunchbase Terms of Service.
Final thoughts
A DIY Crunchbase scraper can be an exciting project and gives you full control over the data extraction process. But be mindful of the challenges that come with it. Facing a roadblock in each step can make scraping a time-consuming and often fragile process that requires technical expertise and constant maintenance.
Proxycurl provides a simpler and more reliable alternative. Follow along with the steps and you can access structured company data through an API without worrying about any roadblocks. Dedicate your time by focusing on using the data and leave the hard work and worry to Proxycurl!
We'd love to hear from you! If you build something cool with our API, let us know at [email protected]! And if you found this guide useful, there's more where it came from - sign up for our newsletter!