
So you want to scrape LinkedIn for data. Maybe you're a dev looking to automate your next remote job search, maybe you're a hiring manager trying to find the right candidate, or maybe you're an investor trying to figure out who exactly is joining which stealth ventures. The problem, of course, is that LinkedIn doesn't have a public API, and building your own scraper from scratch is really hard.
In this guide, we'll go over the DIY solution in case you want to try it yourself despite the difficulty. And after that, I'll walk you through the old Proxycurl approach, using Postman, Python, and JavaScript, because the original tutorial is still technically useful if you are maintaining legacy code or trying to understand the shape of the problem. If you're here for the modern answer, stick around for the NinjaPear section appended where Proxycurl is discussed.
Here's what we'll cover:
- What's required to scrape LinkedIn yourself: understanding public vs private profiles, scraping HTML, dealing with the authwall, and more.
- What the old Proxycurl API accepted, and what it returned.
- How to query the Person Profile Endpoint in Postman, Python, and JavaScript.
- A measure of reliability: querying the Person Profile Endpoint 100 times and looking at the status codes.
- What to use now that Proxycurl has been sunset, namely NinjaPear's richer B2B data APIs that do not scrape LinkedIn and carry none of the legal liability.
How would you build a LinkedIn scraper in a vacuum?
First, we must understand the difference between public and private profiles on LinkedIn. In a nutshell, it's only safe and legal to scrape public profiles. Companies that scrape private profiles have faced lawsuits from LinkedIn. On the other hand, public profiles sit in a different bucket legally, but if you've been in this space long enough, you know that "legal" and "safe to build a company on" are not the same thing.
So if we limit ourselves to public profiles we will be okay. But how do we go about actually scraping a profile?
Scraping one field from an example profile
For this article, we saved an example profile locally and wrote a simple scraper to parse out one of the easier fields to retrieve as JSON data: a person's languages. Note that this script is doing nothing to connect to LinkedIn, all it's doing is using BeautifulSoup to scrape one field. Here's the code:
def get_languages(raw_html: BeautifulSoup) -> List[str]:
languages = []
language_section = [_ for _ in raw_html.body.main.find_all('section') if _.get('data-section') == 'languages']
if len(language_section) == 0:
return languages
for language in language_section[0].div.ul.find_all('li'):
languages.append(language.div.h3.get_text().strip())
return languages
Depending on your level of experience with web scraping, this may seem like a lot of work for just a single field, or it may not seem too bad. Either way, keep in mind that you also have to:
- Do this for every single field you're interested in.
- Keep up with a moving target. Any time LinkedIn rearranges its HTML, you'll have to adjust your parser, sometimes significantly, and sometimes all at once.
- Support internationalization. For example, Czech-language profiles need a dedicated parser.
That last point gets underestimated. A scraper that works on your own test profile is not a product. It is a demo. The painful part starts when you need it to keep working across profile variants, languages, sparse profiles, weird edge cases, and whatever experiment LinkedIn is currently running in production.
Authwall: what is it and how do we deal with it?
Go into incognito mode and try browsing some LinkedIn profiles. Go on, I'll wait. Chances are, within one or two clicks you arrived at something that looks like this:
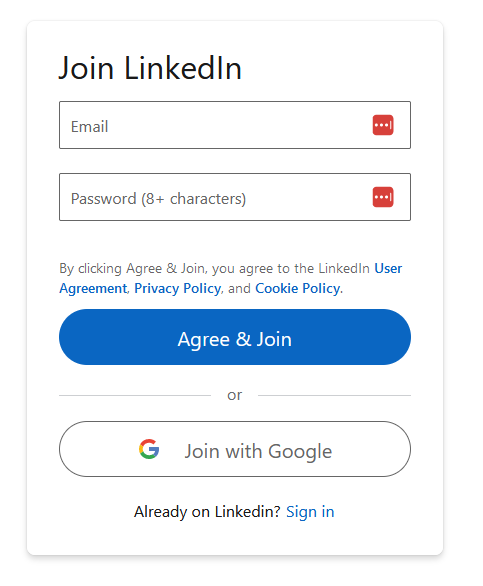
LinkedIn's authwall blocks you from seeing most profiles while you're logged out.
That's the authwall. Even if a LinkedIn profile is public, you still need to be logged in if you want to see it consistently. We can access it in code like this:
import requests
from bs4 import BeautifulSoup
def has_authwall(url: str) -> bool:
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
for s in soup.find_all('script'):
if '/authwall?trk=' in s.get_text():
return True
return False
(Note that we're still using BeautifulSoup here instead of raw searching for the string in case someone decided to troll us by including the raw string /authwall?trk= in their profile. Hey, it could happen.)
Although this is how to detect the authwall, actually bypassing it is a lot more complicated and out of the scope of this article. I'm not going to publish bypass instructions here. That's where the article stops being a tutorial and starts becoming a liability.
Scraping LinkedIn yourself is hard, but scraping LinkedIn doesn't have to be
As you may be concluding, it's really hard to DIY a LinkedIn scraper. That's why Proxycurl used to exist. It took care of the moving HTML, public profile extraction, parsing, and the ugly reliability work for you.
Update: Proxycurl has been sunset. I founded Proxycurl, and I now work on NinjaPear. I'm leaving the Proxycurl material below in place because the tutorial still explains the shape of the LinkedIn scraping problem well, and some legacy integrations still exist in the wild. But if you are building something new in 2026, do not start with a LinkedIn scraping dependency. Use NinjaPear instead. It gives you rich B2B data in the same general JSON-first shape, without scraping LinkedIn and with none of the legal liability.
If your actual need is person enrichment, company intelligence, employee counts, work emails, customer lists, competitor monitoring, or updates on companies, NinjaPear covers those workflows with public-web sourcing rather than LinkedIn dependency.
What did you put into the Proxycurl API, and what did you get out?
What you had
Proxycurl was a paid API, and you had to authenticate every request with a bearer token, your API key. Back when Proxycurl was live, signing up gave you trial credits so you could experiment a bit.
If you've been paying close attention, you might have noticed I've now said two slightly different things. I mentioned the Person Profile Endpoint in the introduction, and then here's the Person Lookup Endpoint. Yes, these were different endpoints, and yes, they returned different things.
For the purposes of this tutorial, let's concern ourselves with the Person Profile Endpoint, because it was the cleanest one to show off. It assumed you had a LinkedIn URL and you wanted to get a bunch of information about that person.
What you got
What you got was a response in JSON format. No parsing of any sort was needed. Even timestamps were given to you as objects, so you could feed them to datetime without doing string parsing.
Exactly how much was that "bunch" of information? It depended on how much any given person had made available on their profile. First of all, the user had to make their profile public in the first place, private profiles would 404. You were never charged for a request that returned an error code.
Some fields people cared about most included:
experienceslanguagescitystatevolunteer_workpeople_also_viewed
There was a bit more, though. Proxycurl could attempt to go above and beyond, and scrape the following fields if you requested them:
skillsinferred_salarypersonal_emailpersonal_contact_numbertwitter_profile_idfacebook_profile_idgithub_profile_idextra
Each of these additional fields came at an additional credit cost, so you did not request them unless you required them.
What to use now instead
If you are reading this article today, the modern replacement is not "new Proxycurl." There is no new Proxycurl. There is NinjaPear, and it solves the broader business problem better.
The shift matters.
Proxycurl was built around LinkedIn-shaped workflows. NinjaPear is built around public-web B2B intelligence. In practice, that means you can still get structured person and company data, but you are no longer anchoring your product to LinkedIn as the upstream dependency.
Relevant NinjaPear endpoints if you came here looking for the same kind of outcome:
- Person Profile Endpoint via the Employee API: takes a work email, name + company, or role + company and returns a structured profile with work history, education, location, social handles, and more.
- Work Email Lookup: if your real goal is contactability, this is often the better starting point than a profile URL.
- Company Details: company record, industry, founders, executives, addresses, social links.
- Employee Count: fresh headcount via real-time web search.
- Company Updates: blog and X updates in one timeline.
The legal and operational difference is not cosmetic. It is the whole game. I learned that the expensive way.
Example walkthroughs
Now that we know what we're working with, let's look at some examples from the original Proxycurl flow. I'll preserve them mostly as-is because if you're maintaining old code, this is still the fastest way to understand how the integration worked. Then I'll show the NinjaPear equivalent path you should use for anything new.
Postman
We previously posted an in-depth Postman walkthrough for Proxycurl, but you could also follow along directly in the docs back then.
- In the Person Profile Endpoint docs, find the orange button that said Run in Postman and click it. Then click "Fork Collection" and log in however you like.
- Add your Bearer Token to the environment as a variable. Limit it to Proxycurl. You could do this from the Variables tab or from the pop-up that appeared when you started typing into the Token field. You could name this variable anything you liked, but
Bearer Tokenwas a good name. - Verify that the Authorization type was set to
Bearer Tokenand that you had typed{{Bearer Token}}into the Token field, then click Save in the upper right-hand corner. Remember to click Save. - Under "My workspace," expand your Proxycurl collection and then the People API, and double-click the Person Profile Endpoint. You could un-check some of the fields if you wanted or modify others. For example, you might have changed
use_cachefromif-presenttoif-recentto get fresher info. - Once you've modified the fields to your liking, click the blue
Sendbutton.
Troubleshooting Postman
If you got a 401 status code, most likely you forgot to hit Save in Step 3. A good way to troubleshoot this was to see if you could fix it by editing the Authorization tab for this specific query to use the {{Bearer Token}} variable. If that fixed it, auth inheritance probably was not working.
The NinjaPear equivalent
Today, if you want the same developer experience, use NinjaPear's API docs and test the live endpoints with your API key. The docs support plain REST with bearer auth, and the modern equivalent endpoints are under the Employee API and Company API.
The first request I would test is not a LinkedIn URL request. It is one of these:
- Person profile by work email
- Person profile by
name + employer_website - Work email lookup by
name + company - Company details by website
That is a better production habit because it anchors your system to identifiers you actually control in your CRM, not to LinkedIn URLs that may or may not be available.
Python
Let's now try and make the exact same request, only with Python. Here is the old Proxycurl example, preserved with the terminology fixed for LinkedIn:
import os, requests
api_endpoint = 'https://nubela.co/proxycurl/api/v2/linkedin'
api_key = os.environ['PROXYCURL_API_KEY']
header_dic = {'Authorization': 'Bearer ' + api_key}
params = {
'url': 'https://www.linkedin.com/in/johnrmarty/',
'fallback_to_cache': 'on-error',
'use_cache': 'if-present',
'skills': 'include',
'inferred_salary': 'include',
'personal_email': 'include',
'personal_contact_number': 'include',
'twitter_profile_id': 'include',
'facebook_profile_id': 'include',
'github_profile_id': 'include',
'extra': 'include',
}
response = requests.get(api_endpoint, params=params, headers=header_dic)
print(response.json())
What you got was a huge wall of text in your terminal. If you wanted to inspect the actual output using PyCharm, you could change the last two lines to this:
response = requests.get(api_endpoint, params=params, headers=header_dic)
result = response.json()
print(result)
And then put a breakpoint on the print statement and run it with the debugger so you could drill down into every field of the result JSON.
The NinjaPear equivalent in Python
If you're building this today, use NinjaPear's Python SDK or plain REST. The modern pattern looks more like this:
import os
import ninjapear
configuration = ninjapear.Configuration(
host="https://nubela.co",
access_token=os.environ["NP_KEY"]
)
with ninjapear.ApiClient(configuration) as api_client:
api = ninjapear.ContactAPIApi(api_client)
# Example: start with work email lookup when you know the company
response = api.get_work_email(
name="Patrick Collison",
website="https://stripe.com"
)
print(response)
Or, if the person profile itself is what you need, use the Person Profile endpoint in the Employee API. NinjaPear's own docs explicitly call out that it does not scrape LinkedIn and instead aggregates from public web sources. Frankly, that is the better architecture.
JavaScript
The following old code was meant to be pasted into your browser, meaning it wasn't Node.js code. To avoid CORS errors, you would paste it into a page on the Proxycurl domain. IMPORTANT: never paste code into your browser console that you don't understand.
Here is the old code:
const apiKey = "your_api_key_here";
const params = {
url: "https://www.linkedin.com/in/johnrmarty/",
fallback_to_cache: "on-error",
use_cache: "if-present",
skills: "include",
inferred_salary: "include",
personal_email: "include",
personal_contact_number: "include",
twitter_profile_id: "include",
facebook_profile_id: "include",
github_profile_id: "include",
extra: "include",
};
const queryString = new URLSearchParams(params).toString();
const endpoint = `https://nubela.co/proxycurl/api/v2/linkedin?${queryString}`;
fetch(endpoint, {
headers: { Authorization: `Bearer ${apiKey}` },
})
.then((response) => {
if (!response.ok) {
throw new Error(`Network response not ok. Status code: ${response.status}.`);
}
return response.json();
})
.then((data) => console.log(data))
.catch((error) => console.error("Error: " + error));
The NinjaPear equivalent in JavaScript
For new work, I would not paste browser-console code at all. I would use the official SDK in Node.js or your app backend.
var NinjaPear = require("ninjapear");
var defaultClient = NinjaPear.ApiClient.instance;
var bearerAuth = defaultClient.authentications["bearerAuth"];
bearerAuth.accessToken = process.env.NP_KEY;
var api = new NinjaPear.CompanyAPIApi();
api.getCompanyDetails("https://stripe.com").then(function (data) {
console.log(data);
});
If you need person data rather than company data, swap in the Employee or Contact API class and use the appropriate endpoint. Same pattern. JSON in, JSON out. No HTML parsing. No authwall nonsense.
How reliable was Proxycurl?
Finally, let's take a look at reliability. We'll do this in Python. Reusing the same code from above, let's loop the request 100 times:
codes = {}
for _ in range(100):
response = requests.get(api_endpoint, params=params, headers=header_dic)
code = response.status_code
if code not in codes:
codes[code] = 1
else:
codes[code] += 1
print(codes)
Here was the output from the original article:
{200: 100}
In other words, all of them were successful. At the time, that was the point: if you were going to depend on a scraper-backed API, it had to shield you from the operational weirdness upstream.
That said, I would not take a historical reliability anecdote and turn it into a 2026 buying decision. The better 2026 decision is to not build on LinkedIn scraping in the first place.
What I would build now
If I were rebuilding this stack today, I would split the use cases instead of forcing them all through a LinkedIn scraper.
If you need person enrichment:
- Use NinjaPear's Person Profile endpoint when you have a work email, a name + company, or a role + company.
- Use Work Email Lookup when your bottleneck is reachability, not biography.
If you need company intelligence:
- Use Company Details for industry, executives, addresses, and social links.
- Use Employee Count if you care about headcount.
- Use Company Updates if you care about buyer timing and change detection.
If you need competitive intelligence rather than profile scraping:
- Use the Customer API.
- Use the Competitor API.
- Use Company Monitor.
That last category is the one most teams get wrong. They think they need LinkedIn profile data, when what they really need is a signal that Acme just hired a new VP, launched a new pricing page, or expanded into Germany. Different input. Better outcome.
Summary
In this article, we first discussed how to make a DIY LinkedIn scraper. Then we went over the old Proxycurl approach using:
- Postman
- Python
- JavaScript
That material is preserved because it still explains the technical problem well, and some legacy systems still mirror that flow.
But the important update is this: Proxycurl has been sunset, and if you are building something new, you should not start by building a LinkedIn scraper dependency into your product. I say that as the founder of Proxycurl.
Use NinjaPear instead. It provides structured person, company, contact, customer, competitor, and update data from public web sources, in a JSON-first developer-friendly shape, without scraping LinkedIn and with none of the legal liability.
If you are modernizing an old Proxycurl workflow, start with NinjaPear's docs. Pick one real production use case, person enrichment, work email lookup, company details, or company updates, and replace that first. That is the cleanest migration path, and it will save you from rebuilding a brittle scraper stack you probably do not want to own.
