
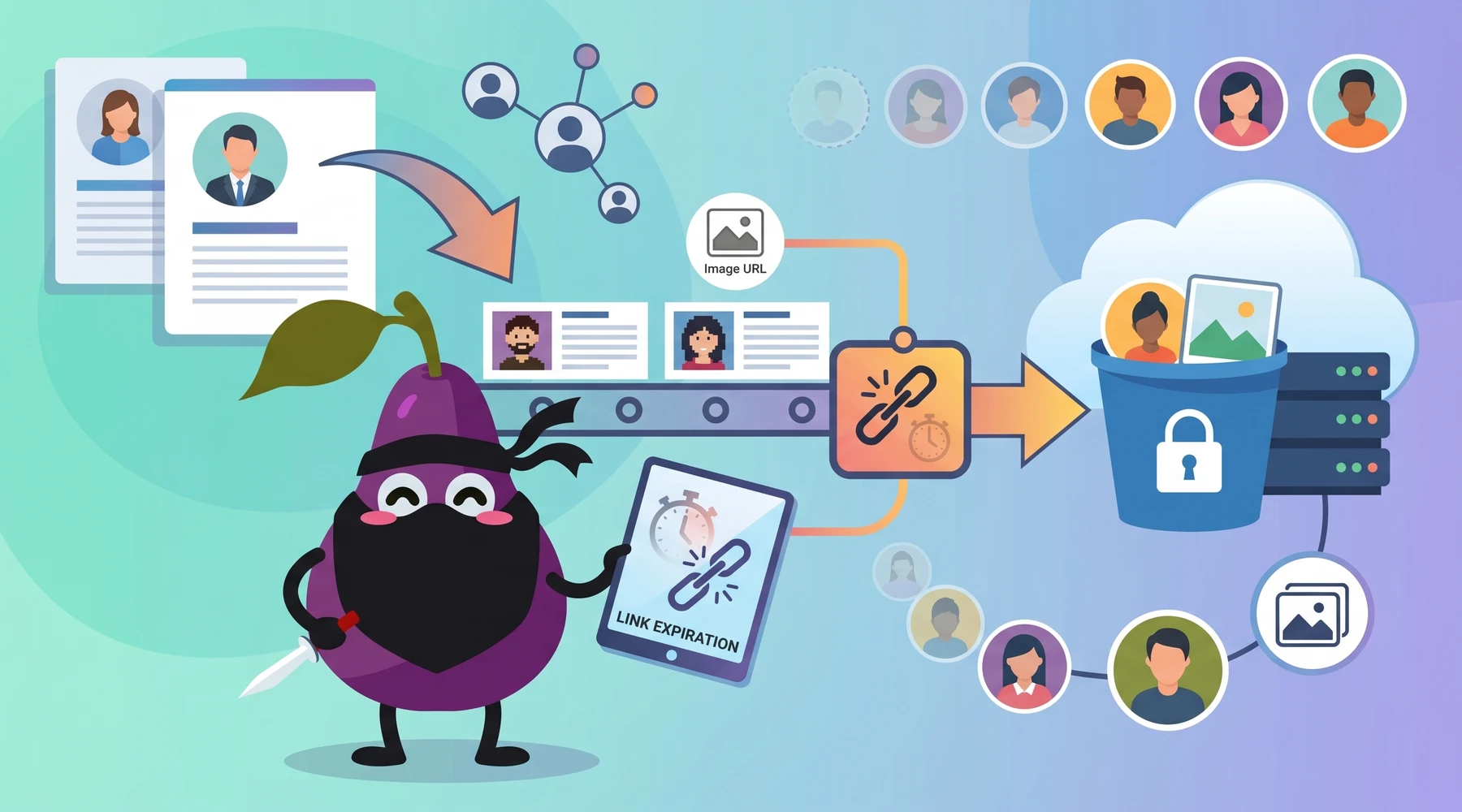
When we scrape a public LinkedIn profile, for example with our Person Profile API, we are served a temporary CDN URL by LinkedIn, which usually begins with https://media-exp.... Some of our customers store that temporary CDN URL directly, and then get burned when it expires in an unpredictable manner. To prevent this, we temporarily cache the image and return an S3 link instead, so the picture URL persists in a predictable fashion. To be precise, 30 minutes.
This is by design, so developers can handle profile images properly by downloading them, instead of relying on LinkedIn's unreliable temporary CDN URLs.
The recommended approach with these temporary links is simple: download the image from the URL returned by our API as soon as you receive the response, then host the image on your end.
Why we do this
LinkedIn does not give us a stable, permanent profile picture URL. What we get upstream is usually a short-lived CDN link. If we were to pass that URL through directly, you would end up storing something that might break minutes later, or later the same day, with no predictable expiry behavior.
So instead, we cache the image briefly on S3 and return that cached link to you. This gives you a small but reliable window to fetch the image and store it yourself.
That 30-minute window is intentional. It is long enough for your application or worker queue to download the image. It is not intended to be permanent asset hosting.
What you should do instead
If you need the profile picture for long-term use, do this:
- Call the API.
- Read the
profile_pic_urlreturned in the response. - Download the image immediately.
- Store it in your own object storage, CDN, or database-backed file store.
- Serve that stored image from your own infrastructure.
That is the correct integration pattern.
If you store our returned S3 URL directly in your database and expect it to remain valid forever, it will break. That is not a bug. That is the expected behavior.
About Proxycurl
Note: Proxycurl API has been sunset. I am the founder behind Proxycurl, and I now work on NinjaPear. If you landed on this post from older Proxycurl documentation or integrations, that is why you are seeing the old product name here in context.
The core behavior described in this article remains the same: when dealing with profile pictures scraped from LinkedIn profiles, you should treat returned image URLs as temporary fetch URLs, not permanent storage.
The short version
The API is returning S3 links for profile pictures scraped from LinkedIn profiles because LinkedIn's own image URLs are temporary, and we need to give you a predictable window to download the image safely.
Download first. Host it yourself after that.
If you are building against NinjaPear now and are unsure how to handle image fields in your pipeline, reach out to us before you bake the wrong storage assumption into production. It is a small implementation detail, but it is exactly the kind of detail that causes annoying failures later.
