
How we enriched 7084 records for two professors and a pHD student of University of Hong Kong University of Science and Technology (HKUST)
A few weeks ago, a student at the University of Hong Kong University of Science and Technology (HKUST) contacted me. The student represented a group of academics who needed to enrich a list of people with work experience and education history.
The following article will share how I did this profile enrichment exercise with Proxycurl API.
The problem
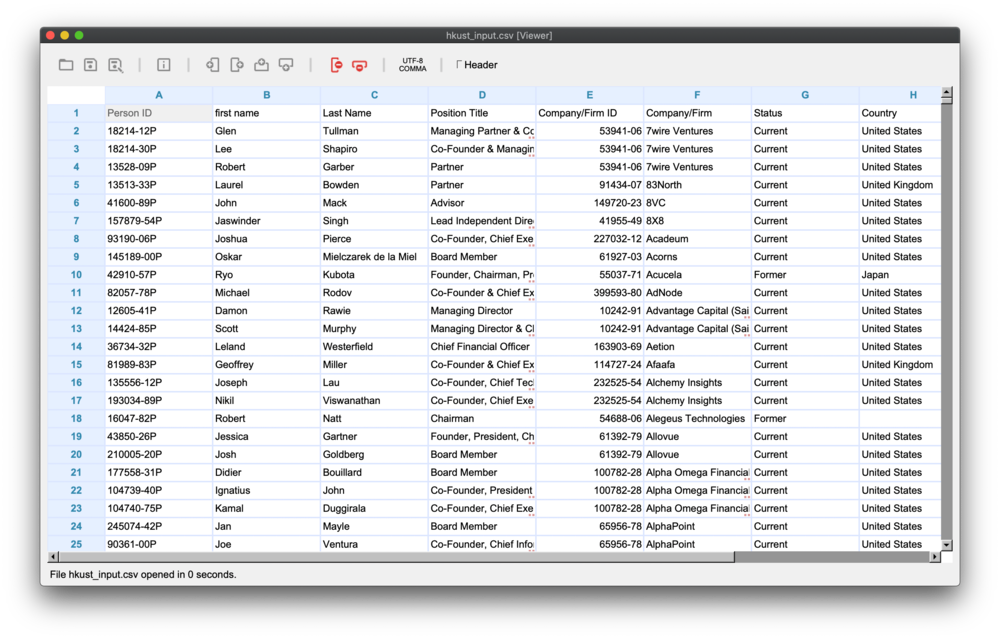
Given a list of people, my job is to find their corresponding Professional Social Network profiles and enrich the list with work and education history.
As it turns out, the data that HKUST provided is outdated.
Resolving people to their Professional Social Network Profile
The list provided by HKUST came with a list of people with general but identifiable information about them. The list includes first names, last names, names of the employer, and their role in their organization. These bits of information are an exact match for Proxycurl's Profile General Resolution Endpoint's input parameters.
To resolve loose bits of information of a person to his/her Professional Social Network profile, I wrote the following function in Python code.
async def resolve_profile_url(first_name, last_name, title, country, city, coy_name, company_domain):
last_exc = Exception()
for _ in range(RETRY_COUNT):
try:
api_endpoint = f'{PROXYCURL_HOST}/api/Professional Social Network/profile/resolve'
header_dic = {'Authorization': 'Bearer ' + PROXYCURL_API_KEY}
async with httpx.AsyncClient() as client:
params = {'company_domain': f"{coy_name} {company_domain}",
'title': title,
'first_name': first_name,
'last_name': last_name,
'location': f"{country} {city}",
}
resp = await client.get(api_endpoint,
params=params,
headers=header_dic,
timeout=PROXYCURL_XHR_DEFAULT_TIMEOUT
)
if resp.status_code != 200:
print(resp.status_code)
assert resp.status_code == 200
return resp.json()['url']
except KeyboardInterrupt:
sys.exit()
except Exception as exc:
last_exc = exc
raise last_exc
With the profile resolution code written, I iterated through a CSV list of people provided by HKUST and got a corresponding match of Professional Social Network profiles.
Bulk scraping Professional Social Network profiles
The next step is the easy step and is Proxycurl's core competency. Now that I have a list of Professional Social Network profiles, all I need to do is send these Professional Social Network profile URLs to Proxycurl's Person Profile Endpoint.
Like the resolution endpoint, I wrote a function that takes a Professional Social Network Profile URL and returns structured data of the profile.
async def get_person_profile(url: str) -> dict:
last_exc = Exception()
for _ in range(RETRY_COUNT):
try:
api_endpoint = f'{PROXYCURL_HOST}/api/v2/Professional Social Network'
header_dic = {'Authorization': 'Bearer ' + PROXYCURL_API_KEY}
async with httpx.AsyncClient() as client:
params = {'url': url}
resp = await client.get(api_endpoint,
params=params,
headers=header_dic,
timeout=PROXYCURL_XHR_DEFAULT_TIMEOUT
)
assert resp.status_code == 200
return resp.json()
except KeyboardInterrupt:
sys.exit()
except Exception as exc:
last_exc = exc
raise last_exc
Proxycurl API tips
You will notice that the functions I wrote are
- asynchronous
- tolerant of unexpected exceptions with a default action of retry
The functions are asynchronous because each request takes an average of 10 seconds. So to maximize throughput, I adopted Proxycurl's best practices. That is to send concurrent requests. In my script, I used 100 workers with Python's `httpx` library to send concurrent asynchronous API requests.
Each request sent to Proxycurl's API is an on-demand scrape job. There is a non-zero chance that a client-side error or network error. When this happens, the right thing to do is always to retry.
With these two tips, I can scrape the entire HKUST file in one go.
Massaging data for output
The team at HKUST needed the output in a specific (Excel) format. After iterating through the list to resolve for Professional Social Network profiles and then fetching their corresponding profile data, we now have the needed raw data. All I need to do now is to massage the raw data into the CSV format that HKUST wanted it in.
And this is how I did it:
def massage_data_for_experience():
with open(PATH_2_OUTPUT, 'r') as output_f:
output_csv = csv.reader(output_f)
counter = 0
for idx, output_row in enumerate(output_csv):
output_id = output_row[0]
profile_json = output_row[1]
profile = json.loads(profile_json)
counter += 1
with open(PATH_2_INPUT, 'r') as input_f:
input_csv = csv.reader(input_f)
for row in input_csv:
input_id = row[0]
if input_id == output_id:
for exp in profile['experiences']:
coy_name = exp['company']
title = exp['title']
employment_type = exp['employment_type']
starts_at = _format_date(exp['starts_at'])
ends_at = _format_date(exp['ends_at'])
description = exp['description']
location = exp['location']
Professional Social Network_profile_url = f"https://www.professionalsocialnetwork.com/in/{profile['public_identifier']}"
with open(PATH_2_EXP, 'a+') as f:
writer = csv.writer(f)
writer.writerow([output_id, coy_name, title, employment_type,
location, starts_at, ends_at, description, Professional Social Network_profile_url])
print(f"{counter}: Done.")
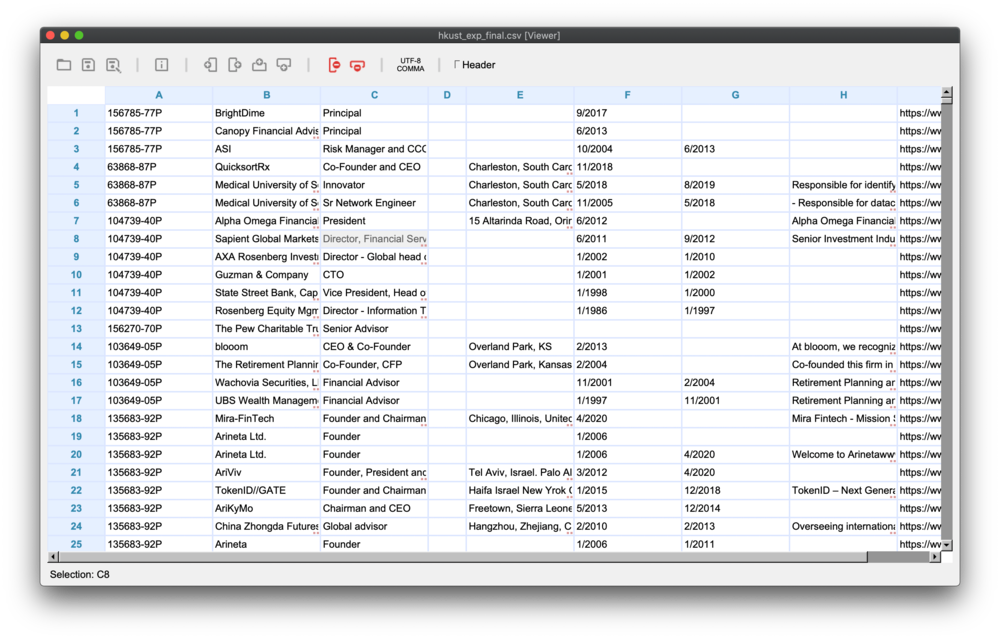
This is how the final result.
Do you have an enrichment task?
Hey, I will love to help you out. Let me know if you have a task at hand that requires bulk Professional Social Network data scraping. You can shoot us an email at [email protected].
Want to hear more stories?
And if you love reading weekly anecdotes as to how we are solving business problems with our data tools, click here to subscribe to our email list :)
