
How to Build a Professional Social Network Data Scraper
So you want to scrape Professional Social Network for data. Maybe you're a dev looking to automate your next remote job search; maybe you're a hiring manager trying to find the perfect candidate; or maybe you're an investor trying to figure out who exactly is joining which stealth ventures. The problem, of course, is that Professional Social Network doesn't have a public API, and [building your own scraper from scratch is really hard](https://nubela.co/blog/tutorial-how-to-build-your-own-Professional Social Network-profile-scraper-2020/).
In this guide, we'll go over the DIY solution in case you want to try it yourself despite the difficulty. And after that, I'll walk you through the Proxycurl API, a SaaS product built precisely to solve the problem you have right now, using Postman, Python, and Javascript. If you're here for an easy solution, feel free to skip to the "answer."
Here's what we'll cover:
- What's required to scrape Professional Social Network yourself? Understanding private vs public profiles, scraping HTML, bypassing the authwall, and more.
- What does the Proxycurl API accept, and what do you get?
- How to query the Person Profile Endpoint in Postman, Python, and Javascript.
- A measure of reliability: We'll query the Person Profile Endpoint 100 times and look at the status codes.
How would you build a Professional Social Network scraper in a vacuum?
First, we must understand [the difference between public and private profiles](https://nubela.co/blog/what-is-the-difference-between-Professional Social Network-public-profiles-vs-Professional Social Network-private-profiles-with-python-code-samples/) on Professional Social Network. In a nutshell, it's only safe and legal to scrape public profiles. Companies that scrape private profiles [have faced lawsuits from Professional Social Network](https://nubela.co/blog/what-you-should-know-now-that-mantheos-a-Professional Social Network-scraping-service-is-sued-by-Professional Social Network/). On the other hand, public profiles [are legal to scrape](https://nubela.co/blog/is-Professional Social Network-scraping-legal/).
So if we limit ourselves to private profiles we will be okay. But how do we go about actually scraping a profile?
Scraping one field from an example profile
For this article, we saved an example profile locally and wrote a simple scraper to parse out one of the easier fields to retrieve as JSON data: A person's languages. Note that this script is doing nothing to connect to Professional Social Network; all it's doing is using BeautifulSoup to scrape one field. Here's the code:
def get_languages(raw_html: BeautifulSoup) -> List[str]:
languages = []
language_section = [_ for _ in raw_html.body.main.find_all('section') if _.get('data-section') == 'languages']
if len(language_section) == 0:
return languages
for language in language_section[0].div.ul.find_all('li'):
languages.append(language.div.h3.get_text().strip())
return languages
Depending on your level of experience with web scraping, this may seem like a lot of work for just a single field, or it may not seem too bad. Either way, keep in mind that we also have to:
- Do this for every single field we're interested in.
- Keep up with a moving target. Any time Professional Social Network rearranges any of its HTML, we'll have to adjust our parser, sometimes significantly, and sometimes all at once.
- Support internationalization. For example, Czech-language profiles need a dedicated parser.
Authwall: What is it and how do we deal with it?
Go into incognito mode and try browsing some Professional Social Network profiles. Go on, I'll wait. Chances are, within one or two clicks you arrived at something that looks like this:
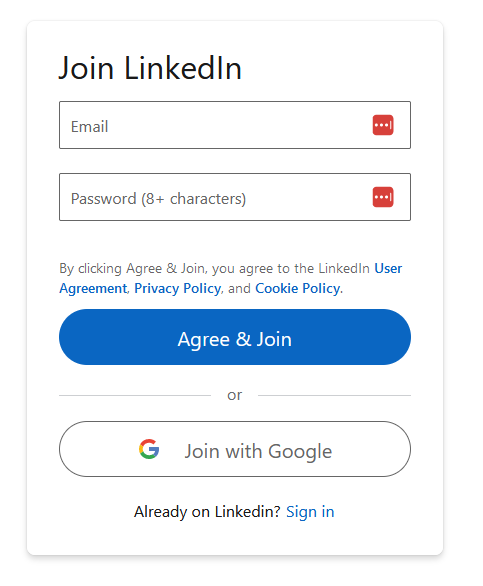
That's the "authwall." Even if a Professional Social Network profile is public, you still need to be logged in if you want to see it. We can access it in code like this:
import requests
from bs4 import BeautifulSoup
def has_authwall(url: str) -> bool:
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
for s in soup.find_all('script'):
if '/authwall?trk=' in s.get_text():
return True
return False
(Note that we're still using BeautifulSoup here instead of raw searching for the string in case someone decided to troll us by including the raw string /authwall?trk= in their profile. Hey, it could happen.)
Although this is how to detect the authwall, actually bypassing it is a lot more complicated and out of the scope of this article; we aren't going to share how Proxycurl does it (sorry!).
Scraping Professional Social Network yourself is hard, but scraping Professional Social Network doesn't have to be
As you may be concluding, it's really hard to DIY a Professional Social Network scraper. That's why Proxycurl exists. We take care of everything for you, and you can take advantage of any one of our many endpoints to retrieve all the data you could possibly want in JSON format.

What do I put into the Proxycurl API, and what do I get out?
What you have
Proxycurl is a paid API, and you need to authenticate every request with a bearer token (your API key). After you've signed up for a Proxycurl account, you can retrieve your API key from the dashboard. Signing up gives you 10 credits, and you'll get another 5 credits upon your first successful query of the Person Lookup API Endpoint, so you can experiment a bit.
If you've been paying close attention, you might have noticed I've now said two slightly different things - I mentioned the Person Profile Endpoint in the introduction, and now here's the Person Lookup Endpoint. What's that all about? Yes, these are different endpoints, and yes, they give you different things. The Proxycurl docs have an ELI5 listing all of our endpoints that gives you a what-you-have-what-you-get directory so you can figure out which one to use. And you thought address books were outdated!
For now, though, let's concern ourselves with the Person Profile Endpoint, this one's just a bit shinier to show off in a tutorial. You can find this endpoint nested under the People API. It assumes you have a Professional Social Network URL and you want to get a bunch of information about that person.
What you get
What you get will be a response in JSON format. No parsing of any sort will be needed. Even timestamps are given to you as objects, so you can feed them to datetime without doing any string parsing.
Exactly how much is that "bunch" of information we mentioned above? It depends on how much any given person has made available on their profile. First of all, the user needs to have made their profile public in the first place; private profiles will 404. You will never be charged for a request that returns an error code.
You can see the full list of standard fields if you scroll a bit down in the Proxycurl Person Profile API docs, but some you might be particularly interested in include experiences, languages, city, state, volunteer_work, people_also_viewed (a list of similar profiles), and other such fields. You can see a full example of any response in the documentation on the right-hand side below the request that generated it.
There's a bit more, though. Proxycurl can attempt to go above and beyond, and scrape the following fields if you request them:
skillsinferred_salarypersonal_emailpersonal_contact_numbertwitter_profile_idfacebook_profile_idgithub_profile_idextra
Each of these additional fields that you request comes at an additional credit cost, so don't request them unless you require them. But when you do need them, Proxycurl puts them a single parameter away!
Example walkthroughs
Now that we know what we're working with, let's look at some examples. We'll start with Postman and Python, since we can pretty much copy-paste these from the Proxycurl docs, and then we'll write a bit of JS code. If these languages aren’t in your wheelhouse, you can also use C sharp for web scraping, or whichever other alternative you’re proficient in. It’s just a case of learning the basics and applying them practically.
Postman
We've previously posted an in-depth Postman walkthrough, but you can follow along here too, and refer to that article if you get stuck.
- In the Person Profile Endpoint docs, find the orange button that says Run in Postman and click it. Then click "Fork Collection" and log in however you like. If you're logging in for the first time, the screen should look something like this:
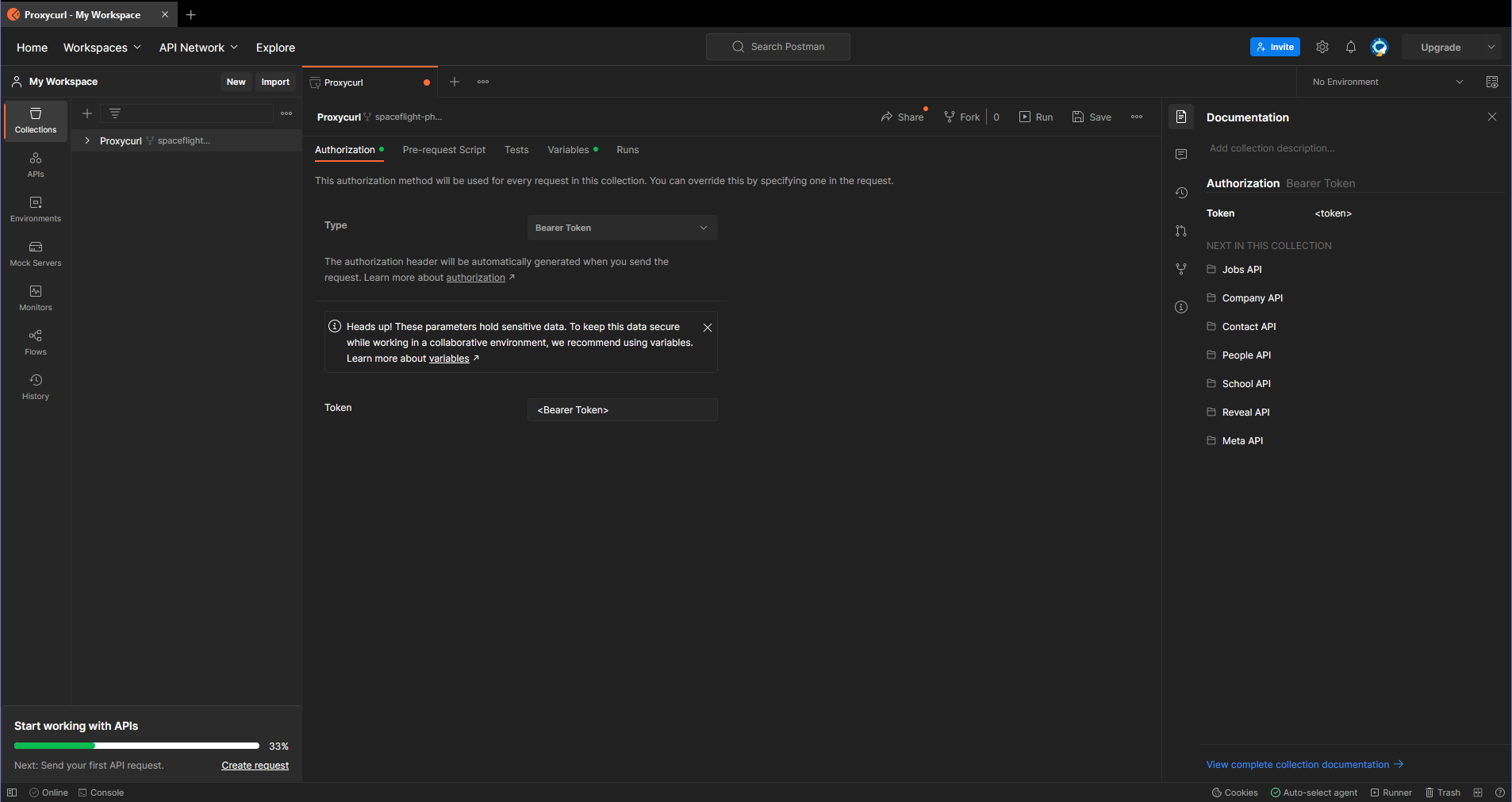
- Add your Bearer Token to the environment as a variable. Limit it to Proxycurl. You can do this from the Variables tab or from the pop-up that appears when you start typing into the "Token" field. You can name this variable anything you like, but
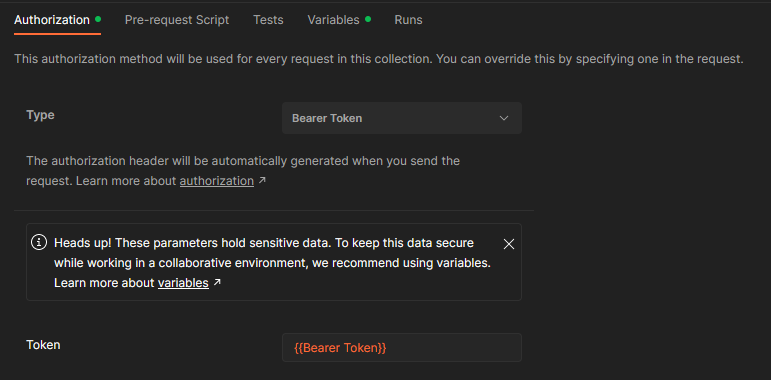
Bearer Tokenis a good name. - Verify that the Authorization type is set to "Bearer Token" and that you have typed
{{Bearer Token}}into the Token field and click Save in the upper right-hand corner. Remember to click Save!! Your page should look like this:
- Now, we should be able to run something! On the left-hand side, under "My workspace," expand your Proxycurl collection and then the People API, and double-click the Person Profile Endpoint. You can un-check some of the fields if you want or modify others - for example, you might want to change
use_cachefromif-presenttoif-recentto get the most up-to-date info, but maybe you don't need the user's personal contact number this time around. - Once you've modified the fields to your liking, click the blue "Send" button in the upper left-hand corner.
Troubleshooting Postman
If you get a 401 status code, most likely you forgot to hit Save in Step 3. A good way to troubleshoot this is to see if you can fix it by editing the Authorization tab for this specific query to be the {{Bearer Token}} variable. If that fixes it, then the auth inheritance isn't working, which probably means you forgot to save.
Python
Let's now try and make the exact same request, only with Python. In the Proxycurl docs, there's a toggle at the top of the page where we can switch between shell and Python. Here is the right-hand side only of the Person Profile Endpoint section, see the upper-left-hand corner of this screenshot:
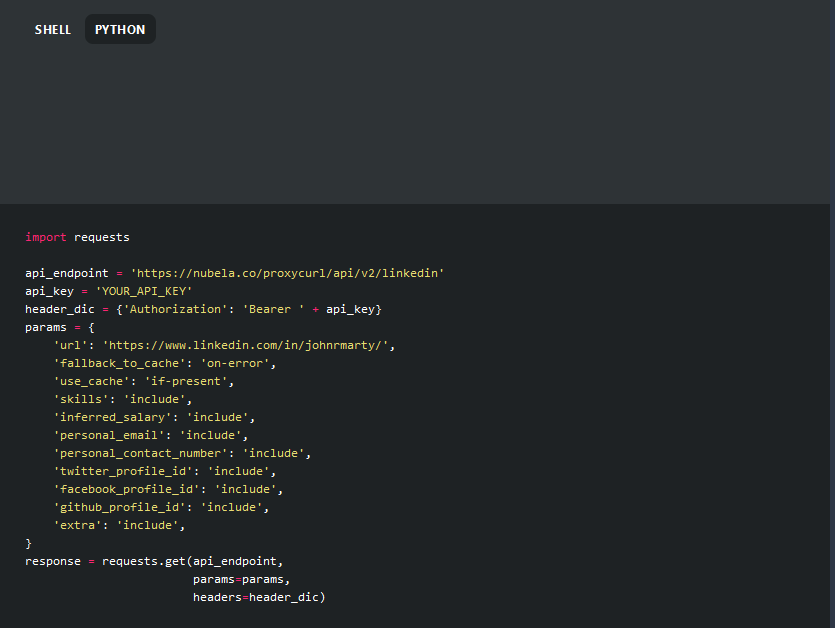
In that screenshot, we can simply paste in our API key where it says YOUR_API_KEY. However, it's best practice to be just a little more careful with secrets than that when you regularly publish your Python code on the internet so we'll do slightly more work. Also, we'll extract the JSON response at the end and print it. Here's the code for all that, and feel free to use this yourself:
import os, requests
api_endpoint = 'https://nubela.co/proxycurl/api/v2/Professional Social Network'
api_key = os.environ['PROXYCURL_API_KEY']
header_dic = {'Authorization': 'Bearer ' + api_key}
params = {
'url': 'https://www.professionalsocialnetwork.com/in/johnrmarty/',
'fallback_to_cache': 'on-error',
'use_cache': 'if-present',
'skills': 'include',
'inferred_salary': 'include',
'personal_email': 'include',
'personal_contact_number': 'include',
'twitter_profile_id': 'include',
'facebook_profile_id': 'include',
'github_profile_id': 'include',
'extra': 'include',
}
response = requests.get(api_endpoint, params=params, headers=header_dic)
print(response.json())
What we get is a huge wall of text in our terminal. But what if we could, say, put a breakpoint and inspect the actual output using PyCharm? Let's give it a try. Change the last two lines to this:
response = requests.get(api_endpoint, params=params, headers=header_dic)
result = response.json()
print(result)
And then put a breakpoint on the print statement, and run it with the debugger. And then we can drill down into every field of the result JSON, like so:
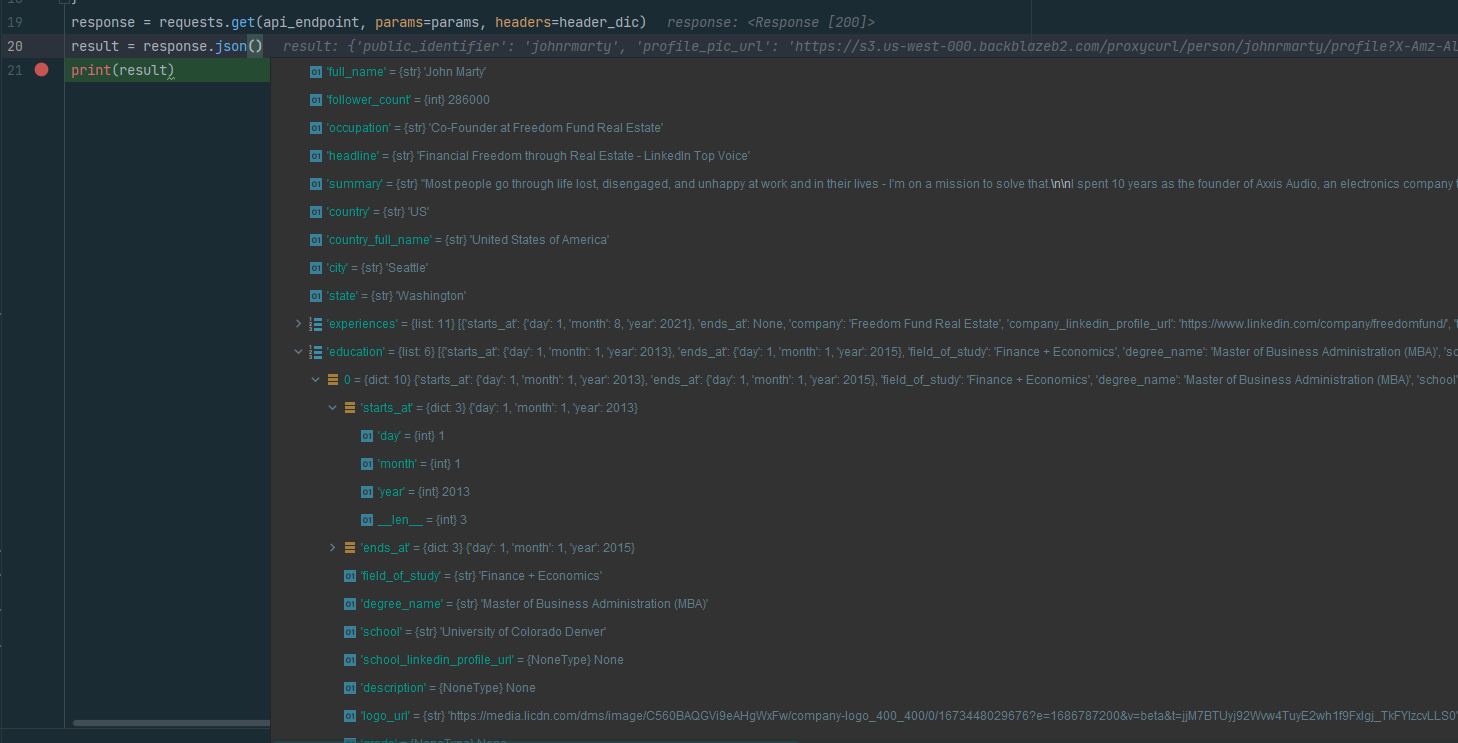
Fantastic! The debugger is an amazing tool, even when there are no bugs in your code and you just want to see the shape of your data.
JavaScript
The following code is meant to be pasted into your browser (i.e. it's not Node.js code). To avoid CORS errors, paste it into a page on the Proxycurl domain, for example the docs page. IMPORTANT: Never paste code into your browser console that you don't understand. This is a major security issue! Ensure you fully understand any JS code you are executing before running it.
Here is an overview of what the code below is doing:
- Generate an object of
paramscorresponding to what we want to fetch in our query. - Transform these params into a query string using URLSearchParams.
- Make the request using fetch, including the bearer token as a header.
- Catch any errors and otherwise print a JSON to the console.
And here is the code:
const apiKey = "your_api_key_here";
const params = {
url: "https://www.professionalsocialnetwork.com/in/johnrmarty/",
fallback_to_cache: "on-error",
use_cache: "if-present",
skills: "include",
inferred_salary: "include",
personal_email: "include",
personal_contact_number: "include",
twitter_profile_id: "include",
facebook_profile_id: "include",
github_profile_id: "include",
extra: "include",
};
const queryString = new URLSearchParams(params).toString();
const endpoint = `https://nubela.co/proxycurl/api/v2/Professional Social Network?${queryString}`;
fetch(endpoint, {
headers: { Authorization: `Bearer ${apiKey}` },
})
.then((response) => {
if (!response.ok) {
throw new Error(`Network response not ok. Status code: ${response.status}.`);
}
return response.json();
})
.then((data) => console.log(data))
.catch((error) => console.error("Error: " + error));
How reliable is Proxycurl?
Finally, let's take a look at reliability. We'll do this in Python. Reusing the same code from above, let's loop the request 100 times:
codes = {}
for _ in range(100):
response = requests.get(api_endpoint, params=params, headers=header_dic)
code = response.status_code
if code not in codes:
codes[code] = 1
else:
codes[code] += 1
print(codes)
Do any of them fail? Here's the output:
{200: 100}
In other words, all of them were successful. In fact, last week when I was writing another post called [Using Proxycurl's Historic Professional Social Network Employee Count Tool for Investment Research](https://nubela.co/blog/using-proxycurls-historic-Professional Social Network-employee-count-tool-for-investment-research/) I was regularly bursting 1500 queries at a time, and I found the API completely reliable, reproducing my results each time I ran the same query. If you enjoyed this article, do check that one out - it shows off a pretty cool application of this API.
Summary
In this article, we first discussed how to make a DIY Professional Social Network scraper. Then we went over how to build a Professional Social Network data scraper easily with Proxycurl using any of the following three methods:
- Postman
- Python
- JavaScript
We introduced you to the Proxycurl Person Profile Endpoint, which returns JSON data to you, so that you don't have to do any text parsing of any kind upon receiving your response. For an overview of the rest of Proxycurl's endpoints, check out the what-you-have-what-you-get ELI5 in the Proxycurl documentation. Now that you know how to use one endpoint, you know how to use them all!
We'd love to hear from you! If you build something cool with our API, let us know at [email protected]! And if you found this guide useful, there's more where it came from - sign up for our newsletter!