Proxycurl is no longer in service. See NinjaPear, a data platform for customer data instead.
The founder of Proxycurl is now working on
NinjaPear, a B2B Customer Data Platform
Redirecting in 3 seconds...









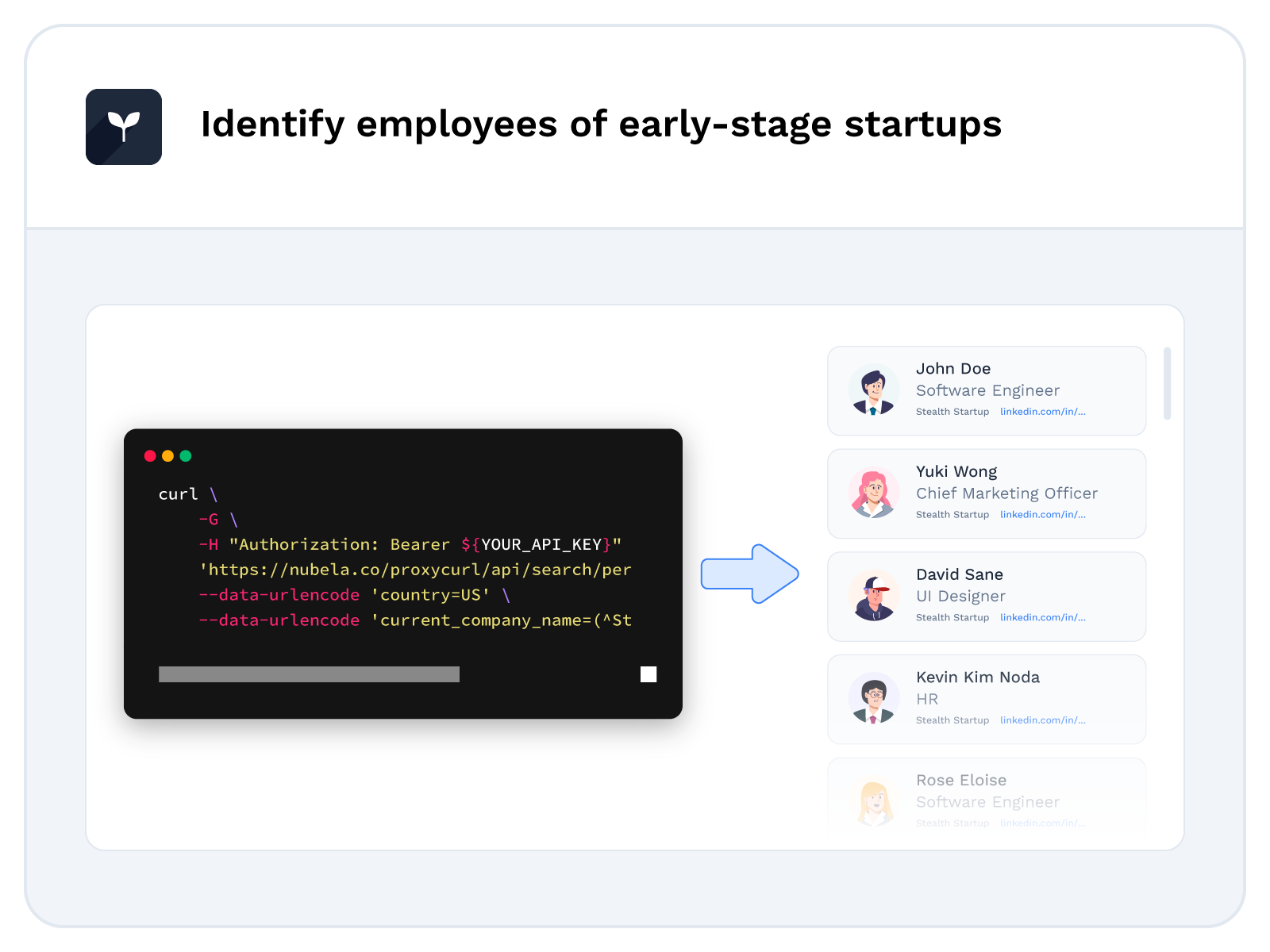
Track and monitor social media profiles for job changes at scale
The distinguishing feature of Lusha and UserGems Buy Signals product is that they are triggered when a Professional Social Network* member changes jobs. Companies such as UserGems and Lusha keep track of job changes on a large scale. One of the companies utilizes Proxycurl APIs to scrape newly-updated Professional Social Network profiles, thereby enhancing their Buy Signals product.
Continue story*Disclaimer: Professional Social Network is a registered trademark of Professional Social Network LLC. Proxycurl is not affiliated with, endorsed by, or sponsored by Professional Social Network LLC.



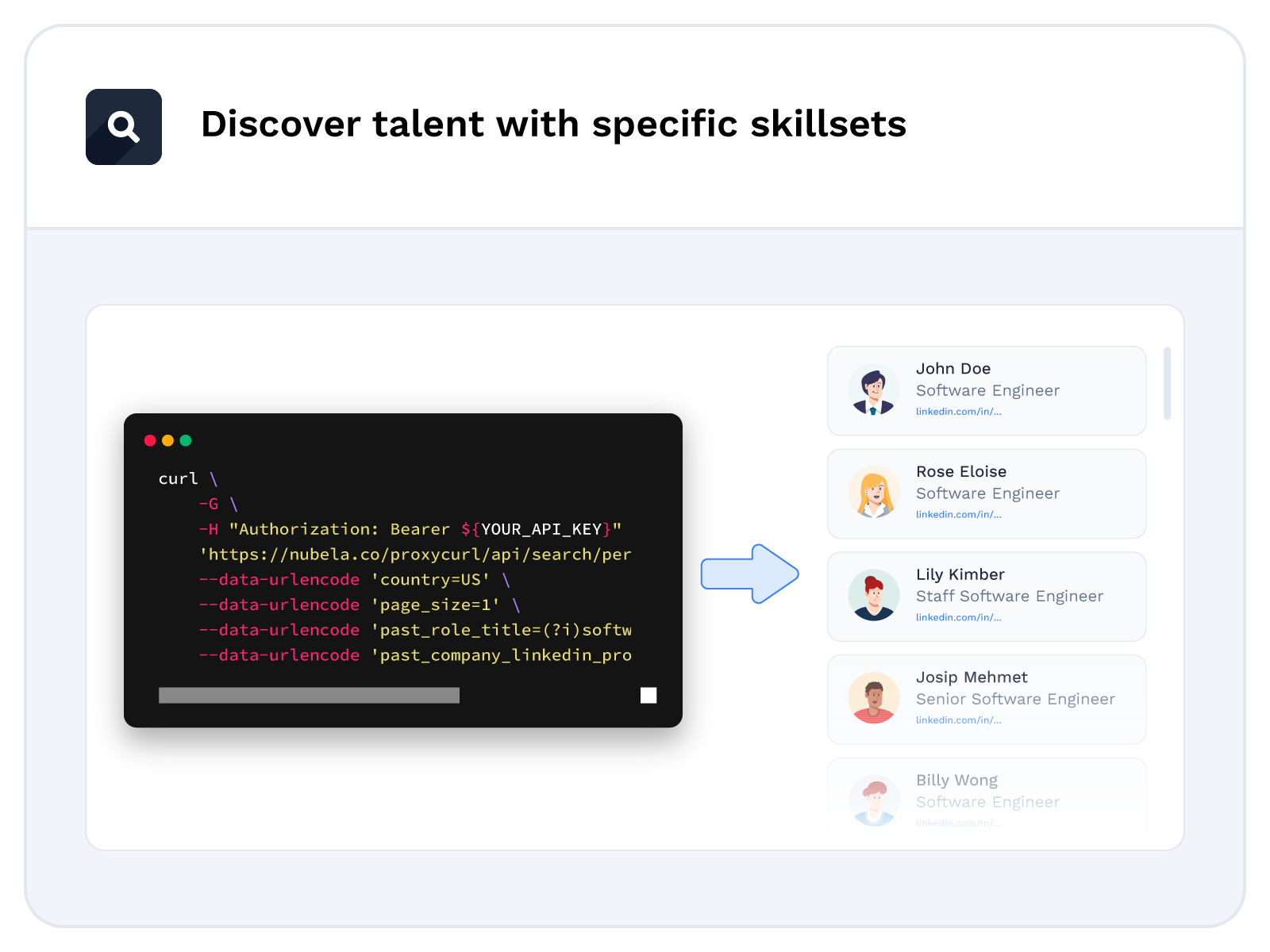
Prospected 14,420 senior marketing candidates for executive hiring
Proxycurl utilized its own Person Search API Endpoint to source for senior marketing candidates across the US, Canada, Singapore, and seven other countries, specifically targeting various growth and marketing-oriented roles in companies with a size of 10-100 employees. The result? A list of 7,209 potential candidates, with their personal emails obtained via the Personal Email Lookup Endpoint.
Following an outreach via cold emails, a Google Form detailing their work history and a video interview, Grace was hired for a senior marketing role, demonstrating Proxycurl's efficient executive talent search process using its own API endpoints.
Continue story
*Disclaimer: Professional Social Network is a registered trademark of Professional Social Network LLC. Proxycurl is not affiliated with, endorsed by, or sponsored by Professional Social Network LLC



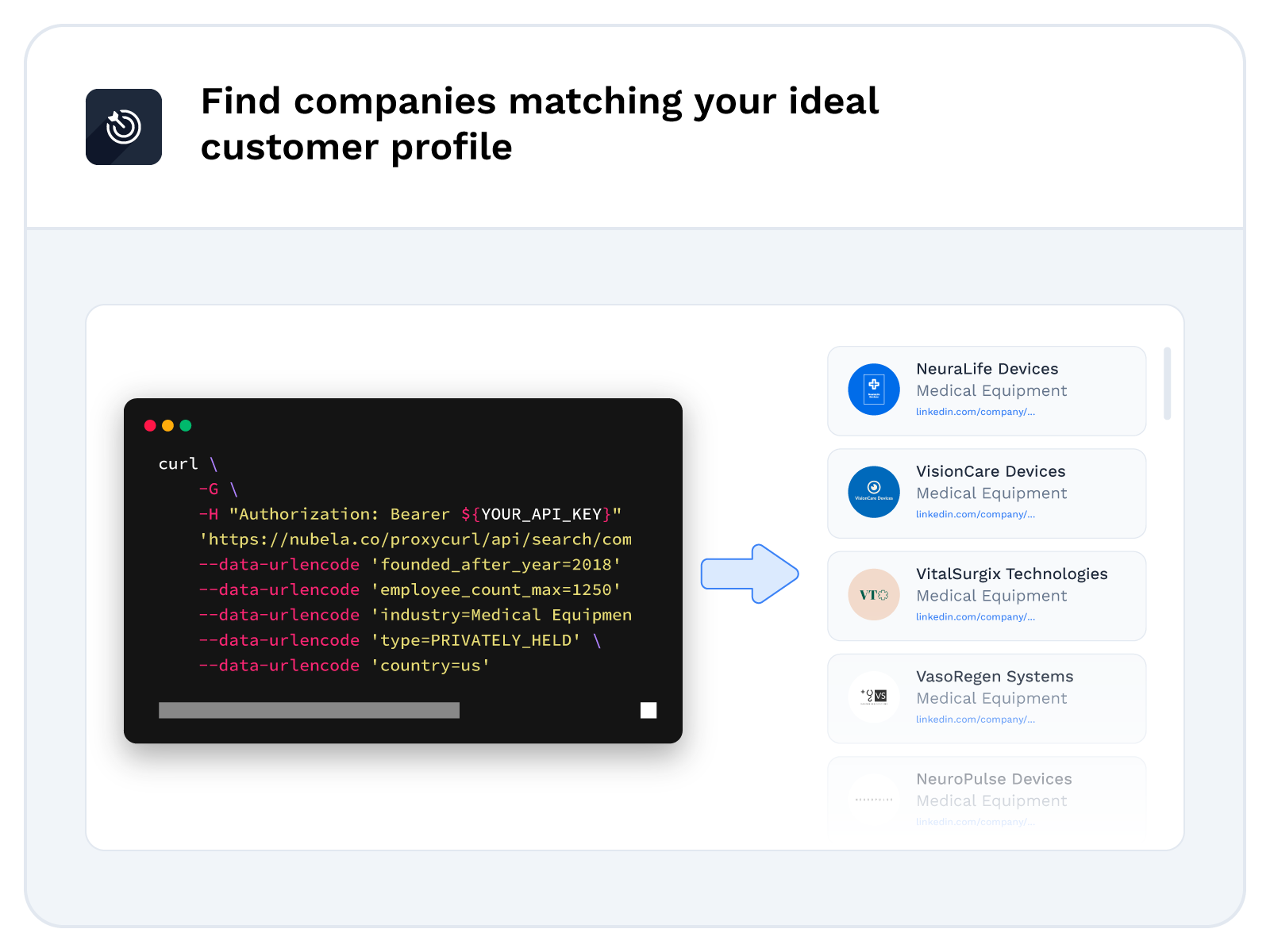
Access B2B data to build sales intelligence applications
The companies Reply.io, Lusha, Apollo, and UpLead all feature prospectors that enable their customers to carry out detailed searches on potential clients. At least one of these companies is a paid user of Proxycurl's LinkDB. With LinkDB, these companies gain access to a comprehensive dataset of public Professional Social Network profiles, providing them with the resources to build a robust prospector within their own applications.
Continue story
Honest reviews from our customers
“Honestly, it was great. Surprisingly simple to set up - didn't realise onboarding a tech could be that easy!”
“Proxycurl is great. It has helped us grow faster.”
“I'm really enjoying Proxycurl so far.”
“We've been using Proxycurl for a couple of months now and so far we've been really satisfied with it.”
"Works great! Now I need to convince my leadership to let me buy a bunch of credits!"
"I like your pricing. Other Professional Social Network solutions are aimed only at enterprise scale."
We abide by strict standards of legal compliance in obtaining data.
On top of that, our security and compliance feature sets rigorous policies in place to safeguard data, uphold information security, and ensure our API is designed with a high bar of security and privacy in mind.
We are CCPA and GDPR compliant and in the process of being SOC 2 certified.
Here's what we've been up to recently.

Learn all about the Professional Social Network API, with comprehensive Python code demos. Dive into the world of Professional Social Network APIs, official and third-party alternatives, and understand how to access and utilize Professional Social Network profile data through Python code examples.
13 MIN READ
I'm happy to share that the team behind Proxycurl is launching Accountgram today! Accountgram is a digital B2B debt collection service with a 32.5% success rate from 64 collections, and an average of 12 days to collection. Accountgram is the key that reduced our customer churn rate
2 MIN READ
As the CEO of Accountgram, a B2B debt collection specialist with 92 collections under my belt since June 2024, I want to provide you with a no-nonsense breakdown of everything I know about B2B collections. I’ll also show you exclusive receipts from a collection made by Atradius, a €2.
12 MIN READ